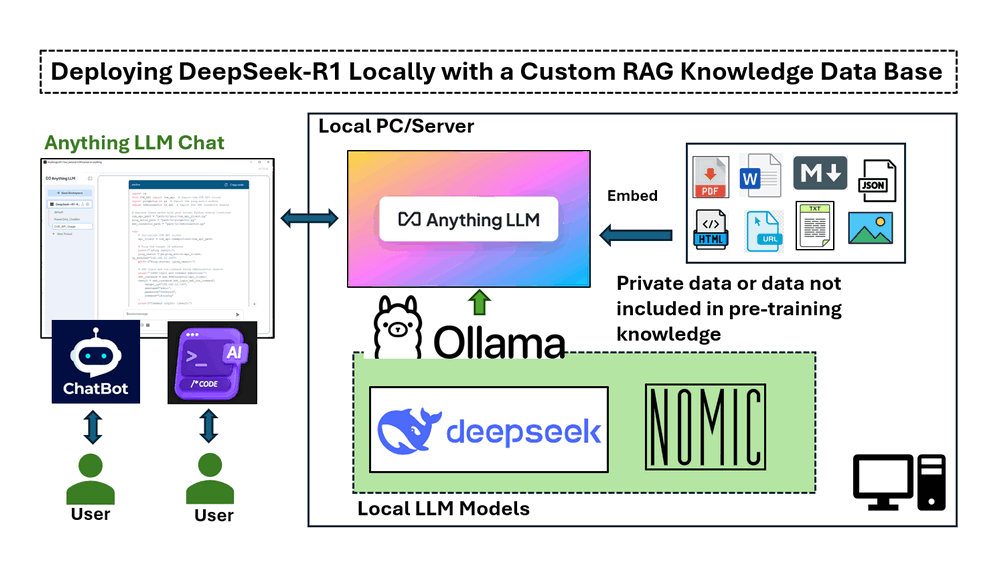
Việc triển khai trong bài viết này bao gồm bốn phần chính:
-
Cài đặt và chạy DeepSeek-R1 cục bộ trên máy Windows với GPU NVIDIA RTX 3060.
-
Thiết lập một pipeline RAG sử dụng nomic-embed-text để truy xuất văn bản dựa trên vector.
-
Triển khai AnythingLLM để tích hợp các phản hồi AI dựa trên tài liệu.
-
Kiểm tra DeepSeek-R1 có và không có RAG, chứng minh tính chính xác của nó trong việc trả lời các truy vấn chuyên biệt.
# Version: v_0.0.1
# Created: 2025/02/06
# License: MIT LicenseGiới thiệu
DeepSeek, một công ty AI của Trung Quốc, đang tạo ra sự đột phá trong ngành với các mô hình ngôn ngữ lớn mã nguồn mở, chi phí thấp, thách thức các gã khổng lồ công nghệ của Hoa Kỳ. Nó đã cho thấy hiệu suất cao trong toán học, mã hóa, hội thoại tiếng Anh và tiếng Trung. Mô hình DeepSeek-R1 là mã nguồn mở (Giấy phép MIT). Bài viết này sẽ khám phá các bước chi tiết để triển khai mô hình DeepSeek-R1:7B LLM trên máy tính xách tay Windows với NVIDIA RTX 3060 (GPU 12GB) để tạo chatbot hỗ trợ AI tùy chỉnh hoặc trình tạo mã chương trình bằng cách sử dụng cơ sở dữ liệu kiến thức Retrieval-Augmented Generation (RAG) và thực hiện so sánh đơn giản giữa câu trả lời LLM thông thường và câu trả lời RAG.
-
Đối với chatbot dịch vụ khách hàng AI, chúng tôi muốn nó cung cấp thông tin dựa trên tài liệu sản phẩm của công ty, biến nó thành một công cụ mạnh mẽ để quản lý kiến thức nội bộ và hỗ trợ khách hàng.
-
Đối với trình tạo mã chương trình AI, chúng tôi muốn nó hỗ trợ phát triển phần mềm bằng cách tạo các đoạn mã dựa trên API chương trình hiện có hoặc nhập các hàm từ thư viện tùy chỉnh.
Để triển khai dự án này, chúng ta sẽ sử dụng bốn công cụ chính:
-
Ollama : Một framework nhẹ, có thể mở rộng để xây dựng và chạy các mô hình ngôn ngữ trên máy cục bộ.
-
DeepSeek-R1 : Một mô hình được đào tạo thông qua học tăng cường quy mô lớn (RL) mà không cần tinh chỉnh có giám sát (SFT) như một bước sơ bộ, đã chứng minh hiệu suất đáng kể về khả năng suy luận.
-
nomic-embed-text : Một mô hình nhúng văn bản mã nguồn mở chuyển đổi văn bản thành các vector số, cho phép máy tính hiểu ý nghĩa ngữ nghĩa của văn bản bằng cách so sánh biểu diễn của nó với những văn bản khác.
-
AnythingLLM : Một chatbot AI mã nguồn mở cho phép người dùng trò chuyện với tài liệu. Nó được thiết kế để giúp các doanh nghiệp và tổ chức làm cho các tài liệu bằng văn bản của họ dễ tiếp cận hơn.
Cách tiếp cận này cải thiện đáng kể quá trình ra quyết định, hỗ trợ kỹ thuật và phát triển phần mềm được hỗ trợ bởi AI bằng cách đảm bảo rằng các phản hồi dựa trên thông tin chuyên biệt, đáng tin cậy.
Kiến thức nền tảng
DeepSeek-R1: LLM mã nguồn mở hiệu suất cao
DeepSeek AI đang tiên phong trong một kỷ nguyên mới của các mô hình ngôn ngữ lớn (LLM) dựa trên suy luận với dòng DeepSeek-R1, được thiết kế để vượt qua các ranh giới về khả năng suy luận toán học, mã hóa và logic. Không giống như các LLM truyền thống dựa nhiều vào tinh chỉnh có giám sát (SFT), DeepSeek AI áp dụng phương pháp tiếp cận học tăng cường (RL) trước tiên, cho phép các mô hình tự nhiên phát triển các hành vi suy luận phức tạp.
Sự phát triển của các mô hình DeepSeek-R1
-
DeepSeek-R1-Zero là mô hình thế hệ đầu tiên được đào tạo hoàn toàn thông qua học tăng cường quy mô lớn (RL), cho phép nó tự xác minh, phản ánh và tạo ra chuỗi suy nghĩ dài (CoT) mà không cần SFT. Tuy nhiên, nó phải đối mặt với những thách thức như trộn lẫn ngôn ngữ, các vấn đề về khả năng đọc và đầu ra lặp đi lặp lại.
-
DeepSeek-R1 đã cải thiện điều này bằng cách kết hợp dữ liệu khởi động nguội trước khi đào tạo RL, dẫn đến một mô hình tinh tế và phù hợp với con người hơn với hiệu suất tương đương với OpenAI-o1 trên nhiều tiêu chuẩn suy luận khác nhau.
Liên kết tham khảo: https://api-docs.deepseek.com/
Tìm hiểu về Retrieval-Augmented Generation (RAG)
Retrieval-augmented generation là một kỹ thuật để nâng cao độ chính xác và độ tin cậy của các mô hình AI tạo sinh bằng thông tin từ các nguồn dữ liệu cụ thể và có liên quan. RAG tăng cường các mô hình AI tạo sinh bằng cách truy xuất dữ liệu bên ngoài trước khi tạo phản hồi, dẫn đến các câu trả lời chính xác hơn, cập nhật hơn và nhận biết ngữ cảnh hơn.
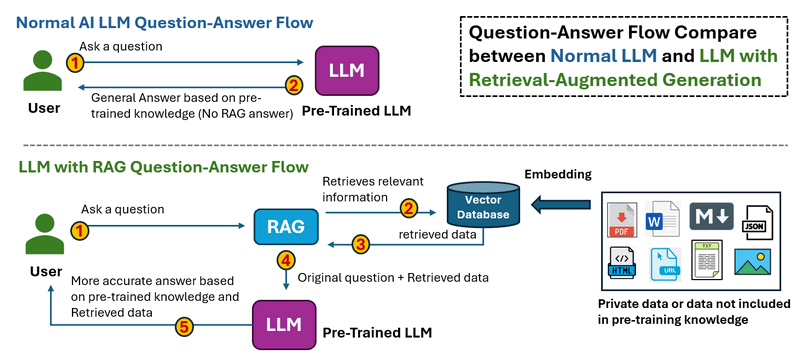
Quy trình làm việc của RAS được hiển thị bên dưới:
-
Trong Luồng Hỏi-Đáp LLM Thông Thường, khi người dùng đặt câu hỏi. LLM xử lý đầu vào và tạo ra câu trả lời chỉ dựa trên kiến thức được đào tạo trước. Không có truy xuất dữ liệu bên ngoài, có nghĩa là thông tin lỗi thời hoặc bị thiếu không thể được sửa chữa.
-
Trong Luồng Hỏi-Đáp LLM với RAG, khi người dùng đặt câu hỏi. Hệ thống trước tiên truy xuất thông tin liên quan từ các nguồn bên ngoài (cơ sở dữ liệu, tài liệu, API hoặc web). Dữ liệu được truy xuất được đưa vào LLM cùng với câu hỏi ban đầu, sau đó LLM tạo ra câu trả lời dựa trên cả kiến thức được đào tạo trước và dữ liệu được truy xuất, dẫn đến các phản hồi chính xác và cập nhật hơn.
Liên kết tham khảo: https://blogs.nvidia.com/blog/what-is-retrieval-augmented-generation/
Bước 1: Triển khai Model DeepSeek-R1 trên Máy cục bộ của bạn
Để thiết lập mô hình DeepSeek-R1 cục bộ, trước tiên bạn cần cài đặt Ollama, một framework mở rộng, gọn nhẹ để chạy các mô hình ngôn ngữ lớn trên máy của bạn. Sau đó, bạn sẽ tải xuống mô hình DeepSeek-R1 phù hợp dựa trên thông số kỹ thuật phần cứng của bạn.
1.1 Cài đặt Ollama
Tải xuống Ollama từ trang web chính thức: https://ollama.com/download, và chọn gói cài đặt cho hệ điều hành của bạn:
Sau khi cài đặt xong, hãy xác minh rằng Ollama đã được cài đặt đúng cách bằng cách chạy lệnh sau trong terminal:
ollama --version
Nếu số phiên bản hiển thị, điều đó có nghĩa là Ollama đã sẵn sàng để sử dụng:
Tiếp theo, hãy khởi động dịch vụ Ollama bằng cách chạy:
ollama serve
1.2 Chọn đúng Model DeepSeek-R1
DeepSeek-R1 cung cấp các mô hình từ phiên bản nhỏ gọn 1,5 tỷ tham số đến mô hình khổng lồ 671 tỷ tham số. Kích thước mô hình bạn chọn phải phù hợp với bộ nhớ GPU (VRAM) và tài nguyên hệ thống của bạn. Trong Ollama web, chọn models sau đó tìm kiếm deepseek như hình bên dưới:
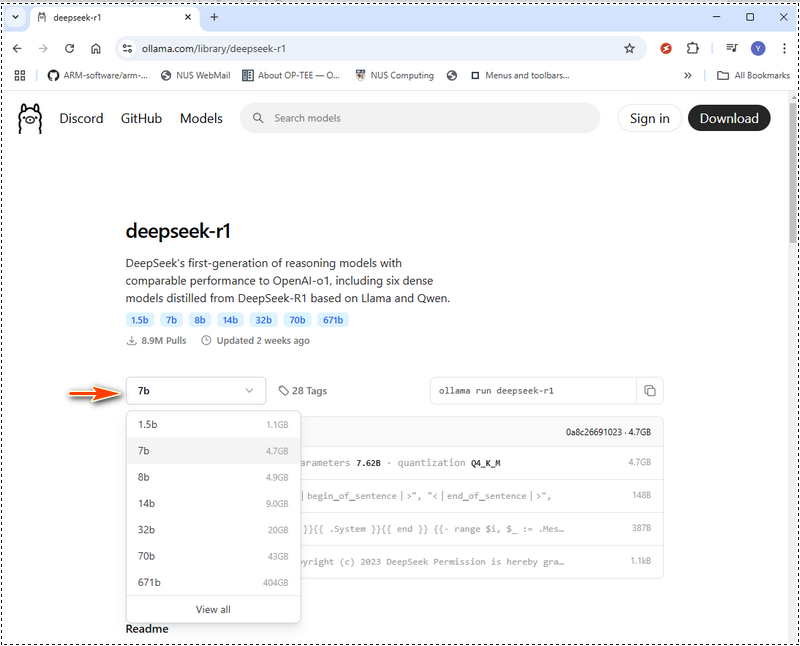
Dưới đây là bảng yêu cầu phần cứng để giúp bạn quyết định mô hình nào nên triển khai. Nếu phần cứng của bạn thấp hơn thông số kỹ thuật được khuyến nghị, bạn vẫn có thể chạy một mô hình lớn hơn bằng cách sử dụng các công cụ tối ưu hóa phần cứng như LMStudio (https://lmstudio.ai/), nhưng điều này sẽ làm tăng thời gian xử lý. Yêu cầu phần cứng của DeepSeek-R1:
| Tên Module | Cấp độ Loại Model | GPU VRAM | CPU | RAM | Đĩa | ||
|---|---|---|---|---|---|---|---|
| deepseek-r1:1.5b | Có thể truy cập | Không yêu cầu GPU hoặc VRAM chuyên dụng | CPU không cũ hơn 10 năm | 8 GB | 1.1 GB | ||
| deepseek-r1:7b | Nhẹ | 8 GB VRAM | CPU đơn như i5 | 8 GB | 4.7 GB | ||
| deepseek-r1:8b | Nhẹ | 8 GB VRAM | CPU đơn như i5, i7 | 8 GB | 4.9 GB | ||
| deepseek-r1:14b | Tầm trung | 12 - 16 GB VRAM | CPU đơn (i7/i9) hoặc CPU kép (Xeon Silver 4114 x2) | 16-32 GB | 9.0 GB | ||
| deepseek-r1:32b | Tầm trung | 24 GB VRAM | CPU kép (Xeon Silver 4114 x2) | 32 - 64 GB |
Đối với model 671b, cần khoảng 480 GB VRAM. Cần thiết lập nhiều GPU, với các cấu hình như:
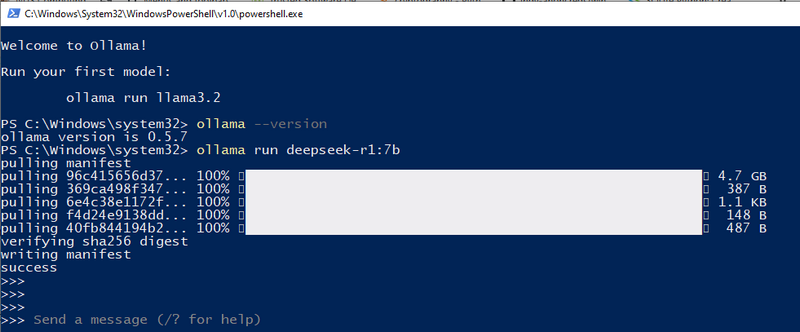
Tham khảo: 1.3 Tải xuống và chạy DeepSeek-R1 Đối với cấu hình cục bộ của tôi, tôi sử dụng 3060GPU(12GB), vì vậy tôi có thể thử 7b. Chúng ta có thể sử dụng ollama run deepseek-r1:7b
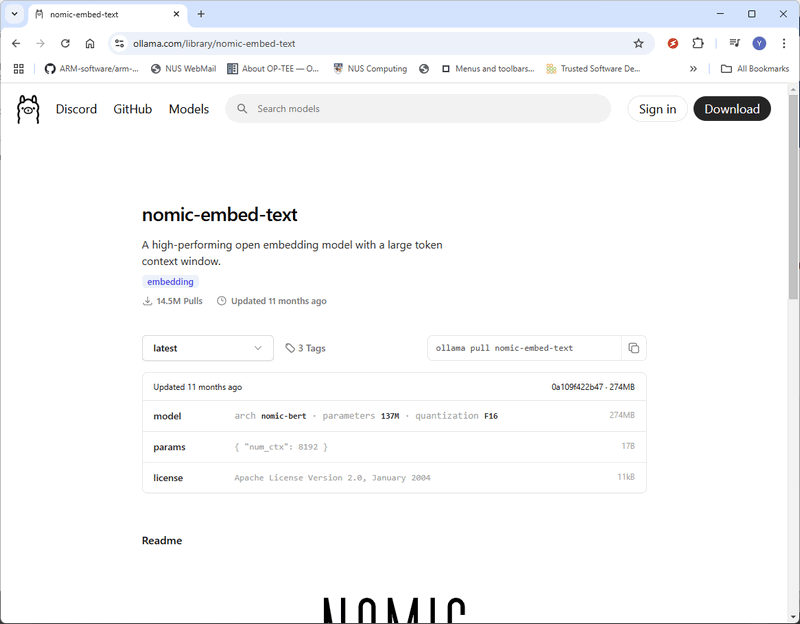
Giờ đây, DeepSeek-R1 đã được triển khai thành công trên máy cục bộ của bạn và bạn có thể bắt đầu đặt câu hỏi AI trực tiếp từ terminal. Bước 2: Cài đặt nomic-embed-textĐể xây dựng cơ sở kiến thức RAG (Retrieval-Augmented Generation), chúng ta cần nomic-embed-text, công cụ chuyển đổi dữ liệu (chẳng hạn như tệp PDF hoặc chuỗi văn bản) thành biểu diễn vector. Các embedding vector này cho phép model AI hiểu các mối quan hệ ngữ nghĩa giữa các đoạn văn bản khác nhau, cải thiện độ chính xác của tìm kiếm và truy xuất. 2.1 Tải xuống nomic-embed-text Truy cập trang chính thức: https://ollama.com/library/nomic-embed-text và tải xuống phiên bản mới nhất như hình bên dưới:
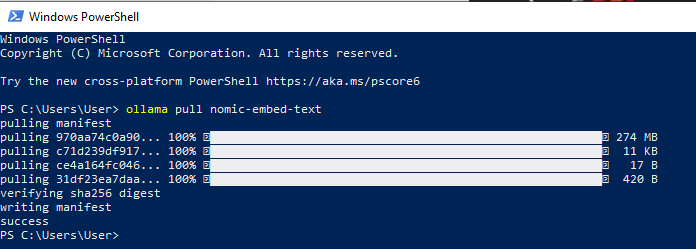
Bạn cũng có thể cài đặt nomic-embed-text trực tiếp bằng lệnh pull của Ollama: ollama pull nomic-embed-text
Bước 3: Cài đặt AnythingLLM và triển khai RAGĐể thiết lập hệ thống RAG (Retrieval-Augmented Generation), chúng ta sẽ sử dụng AnythingLLM, một chatbot AI mã nguồn mở cho phép tương tác liền mạch với tài liệu. 3.1 Tải xuống và cài đặt AnythingLLM Truy cập trang tải xuống chính thức của AnythingLLM: https://anythingllm.com/desktop và tải xuống trình cài đặt phù hợp cho hệ điều hành của bạn.
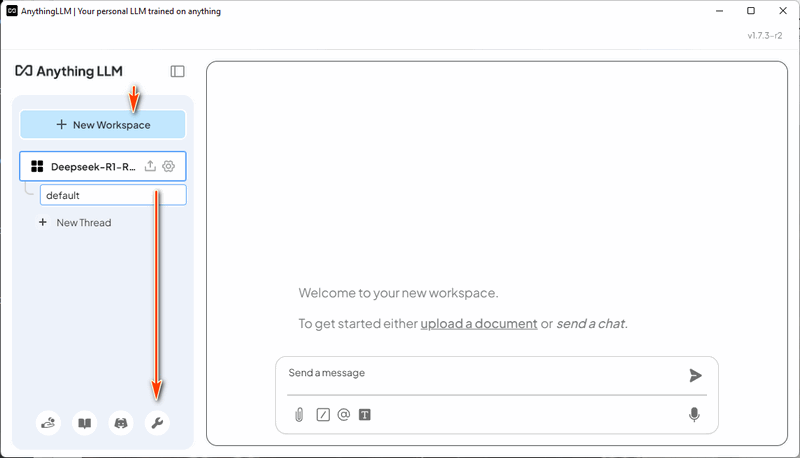
3.2 Tạo Workspace Sau khi cài đặt và chạy AnythingLLM, hãy tạo một workspace mới có tên "DeepSeek-R1-RAG". Sau đó, nhấp vào biểu tượng "Open Settings" cho workspace, như hình bên dưới:
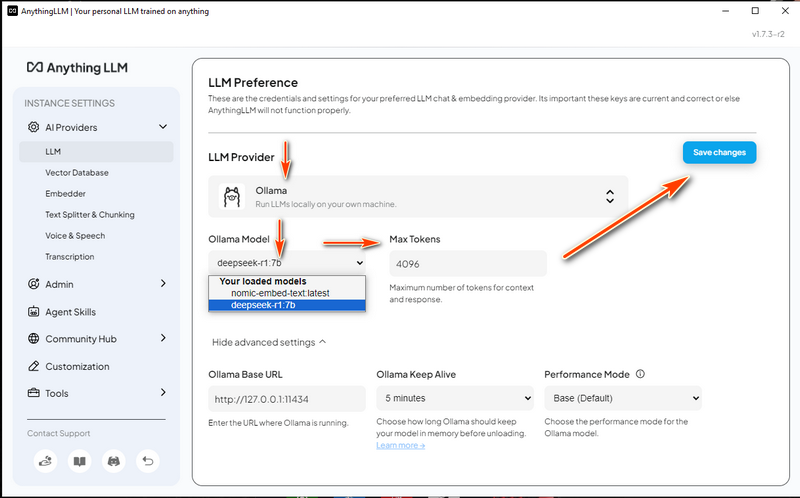
3.3 Cấu hình cài đặt LLM
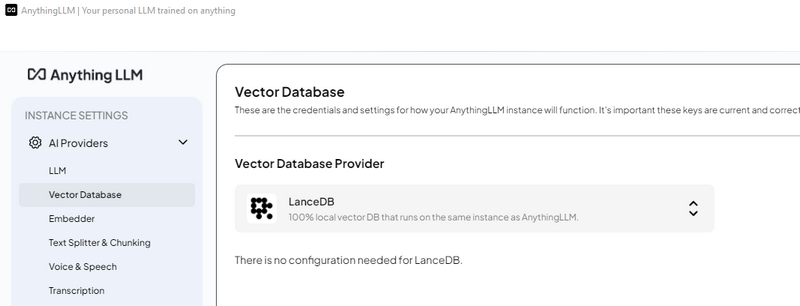
3.4 Cấu hình Vector Database
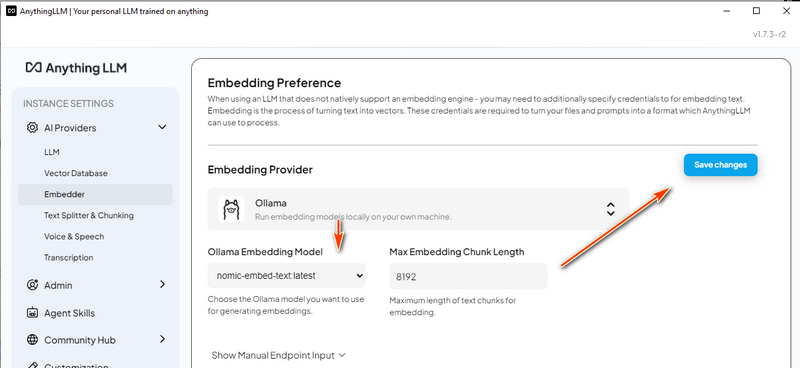
3.5 Cấu hình Embedding Model
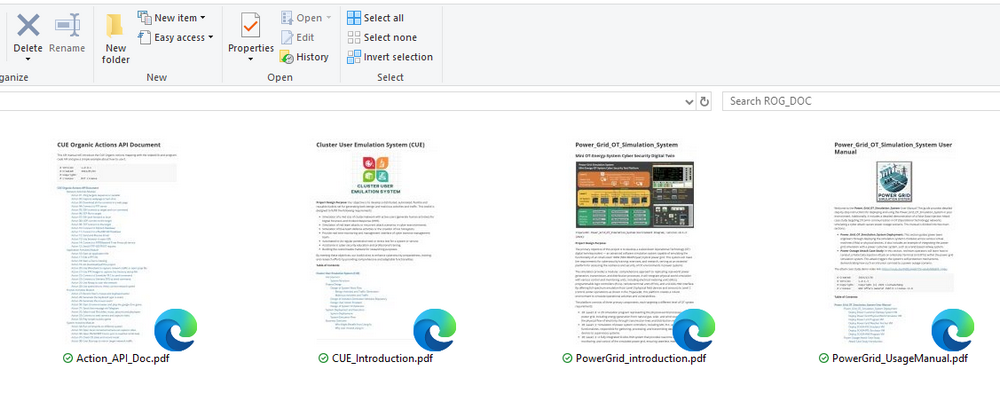
Bước 4: Tải Dữ liệu RAG và Bắt đầu Kiểm traBây giờ chúng ta đã hoàn thành thiết lập, chúng ta có thể tải tài liệu vào hệ thống RAG và kiểm tra chatbot DeepSeek-R1. 4.1 Chuẩn bị Cơ sở Kiến thức Chúng ta sẽ sử dụng bốn tài liệu PDF để xây dựng cơ sở kiến thức của AI:
Tài liệu Hệ thống Mô phỏng Lưới điện
Tài liệu Hệ thống Mô phỏng Hành động Người dùng Cluster (CUE)
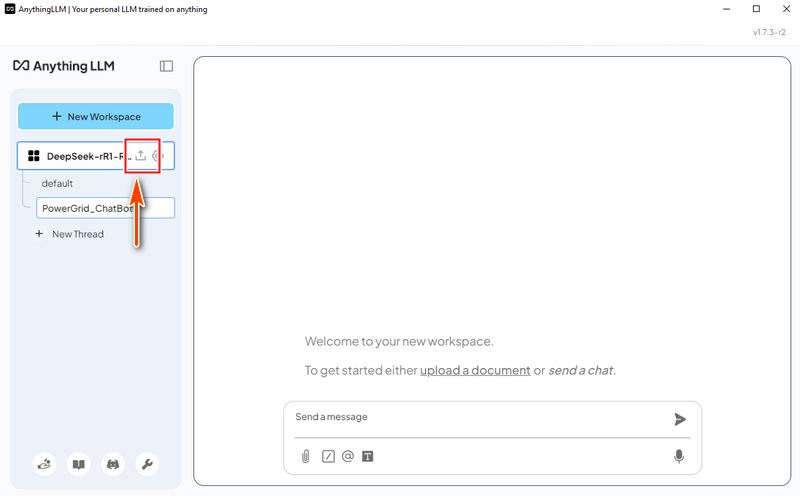
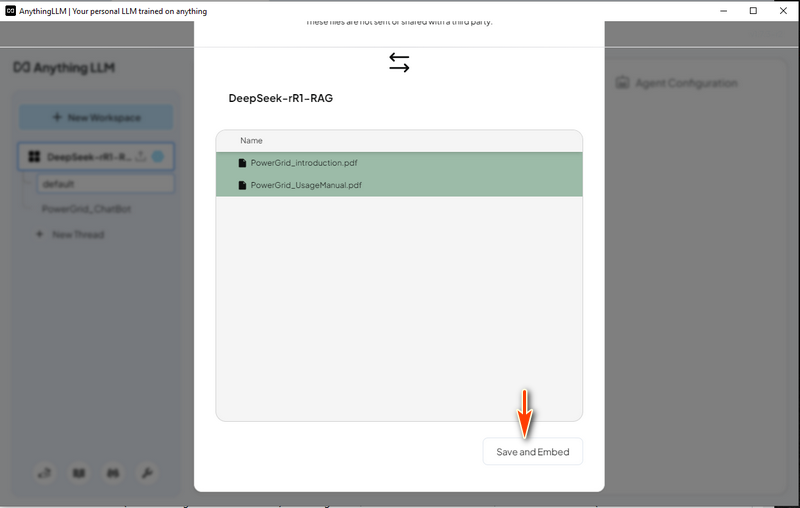
4.2 Tải Dữ liệu Hệ thống Lưới điện Trong AnythingLLM, tạo một luồng "Power Grid Chat Bot" và nhấp vào biểu tượng tải lên:
Sau đó, chọn "Save and Embed" như hình bên dưới, sau khi quá trình hoàn tất, LLM với RAG đã sẵn sàng để sử dụng.
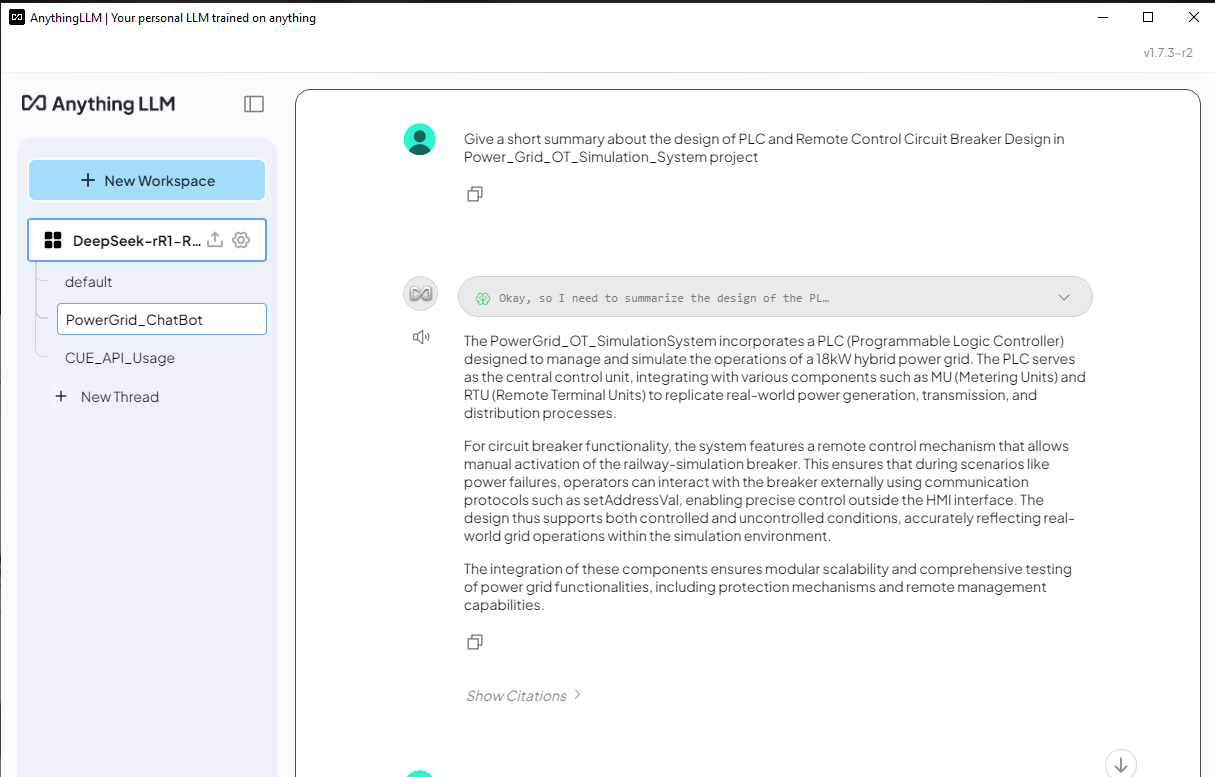
4.3 Kiểm tra DeepSeek-R1 ChatBot với RAG dữ liệu Lưới điện Bây giờ chúng ta có thể thử hỏi DeepSeek-R1 một câu hỏi liên quan đến hệ thống mô phỏng lưới điện và so sánh kết quả giữa câu trả lời có và không có RAG. Câu hỏi: Đưa ra một bản tóm tắt ngắn gọn về thiết kế của PLC và Thiết kế Bộ ngắt mạch Điều khiển Từ xa trong dự án Power_Grid_OT_Simulation_System.
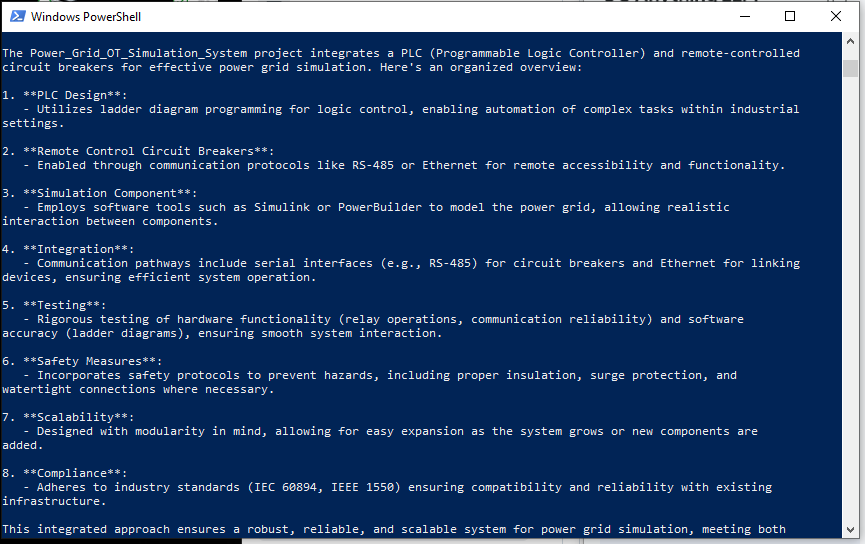
Câu trả lời của DeepSeek-R1 (Không có RAG) - Đối với DeepSeek-R1 không có RAG, nó đã liệt kê một câu trả lời rất chung chung như hình bên dưới và phản hồi không liên quan đến dự án Power_Grid_OT_Simulation_System:
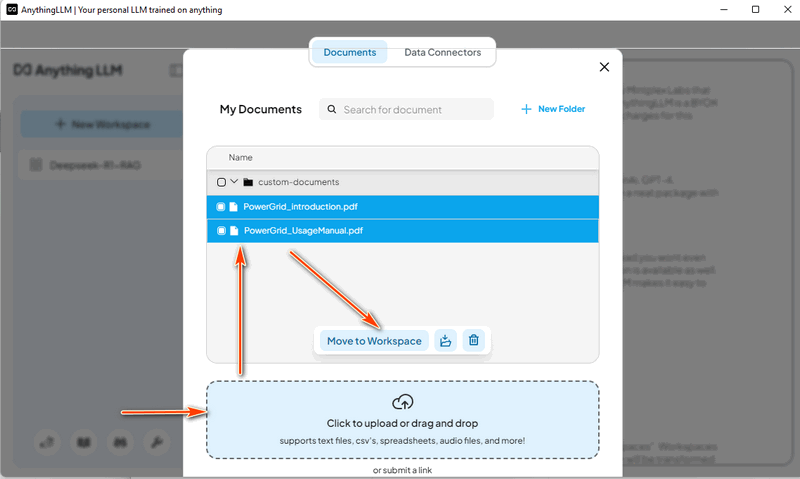
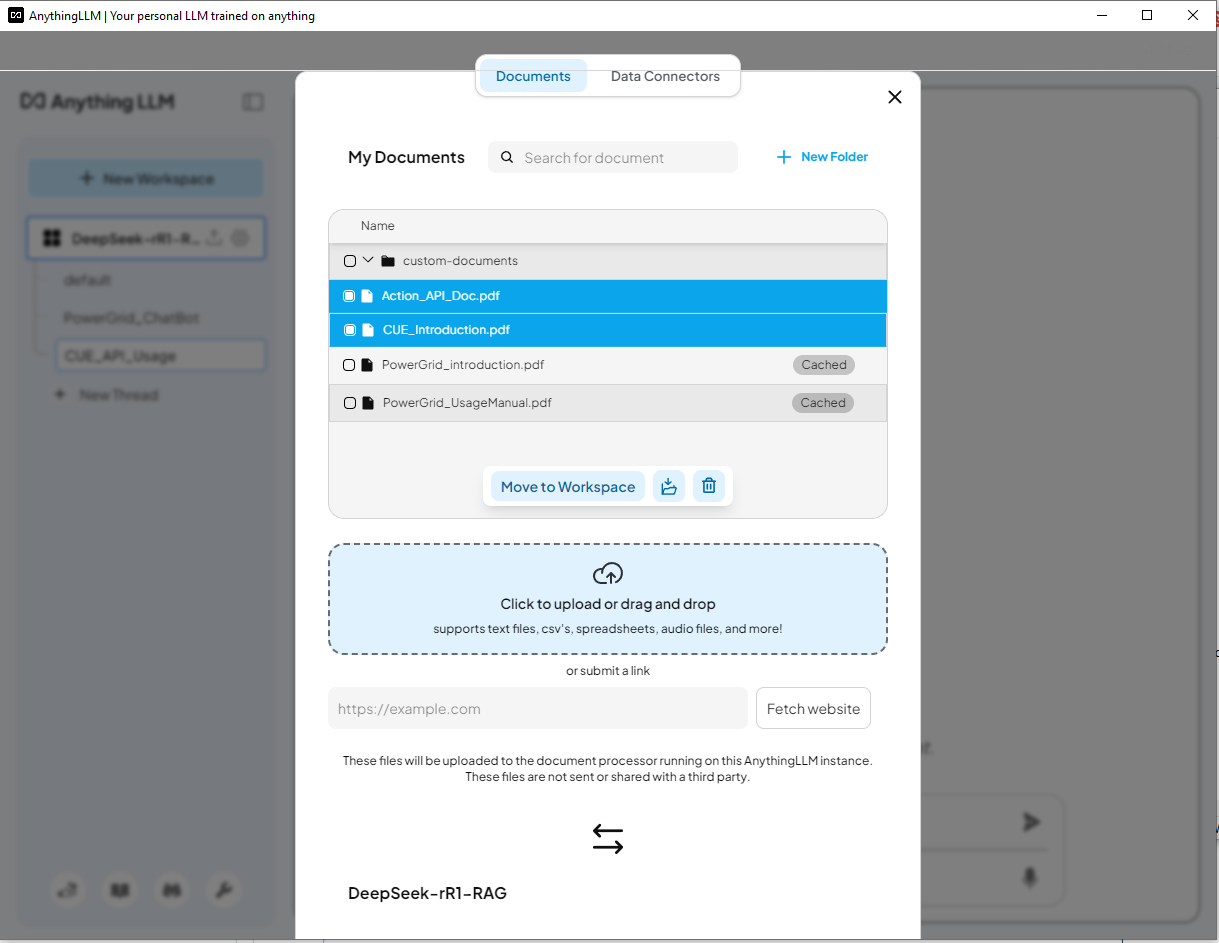
4.4 Tải Dữ Liệu Dự Án Trình Giả Lập Tác Vụ Người Dùng Cụm Lần này, chúng ta loại bỏ tài liệu về lưới điện và tải tài liệu giới thiệu Dự án Trình Giả Lập Tác Vụ Người Dùng Cụm
4.5 Kiểm Tra ChatBot DeepSeek-R1 với dữ liệu CUE Bây giờ chúng ta có thể thử hỏi DeepSeek-R1 một câu hỏi liên quan đến việc tạo một tập lệnh python với hàm lib trong hệ thống mô phỏng tác vụ người dùng cụm. Câu hỏi: Help create a python script/function uses the cluster user emulator(CUE) function API to ping an IP 192.168.10.100 and ssh login to the server with (username: admin, password: P@ssword) to run a command "ifconfig"
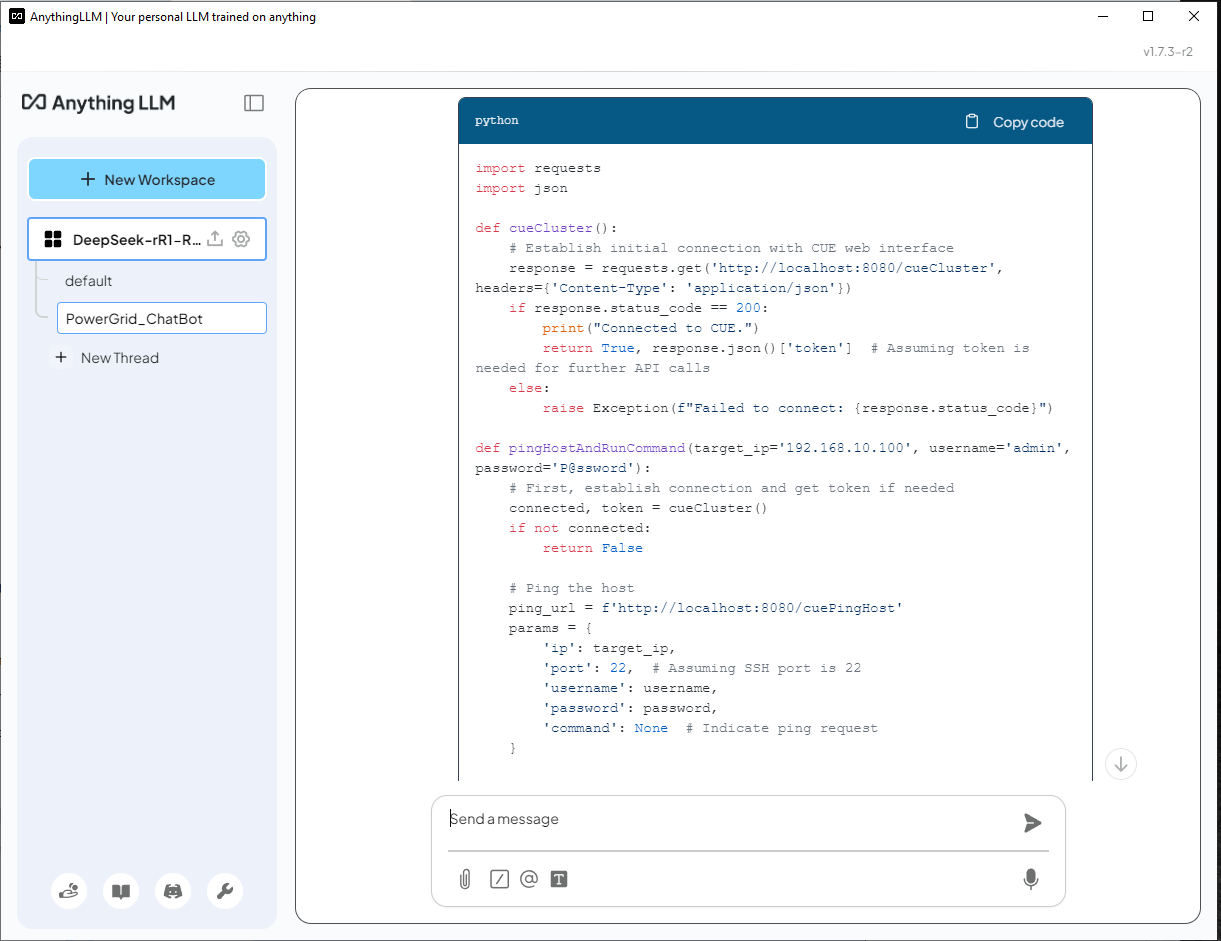
DeepSeek-R1 (Không có RAG) Trả lời - AI không nhận ra CUE và tạo ra một giải pháp không chính xác bằng cách sử dụng thư viện
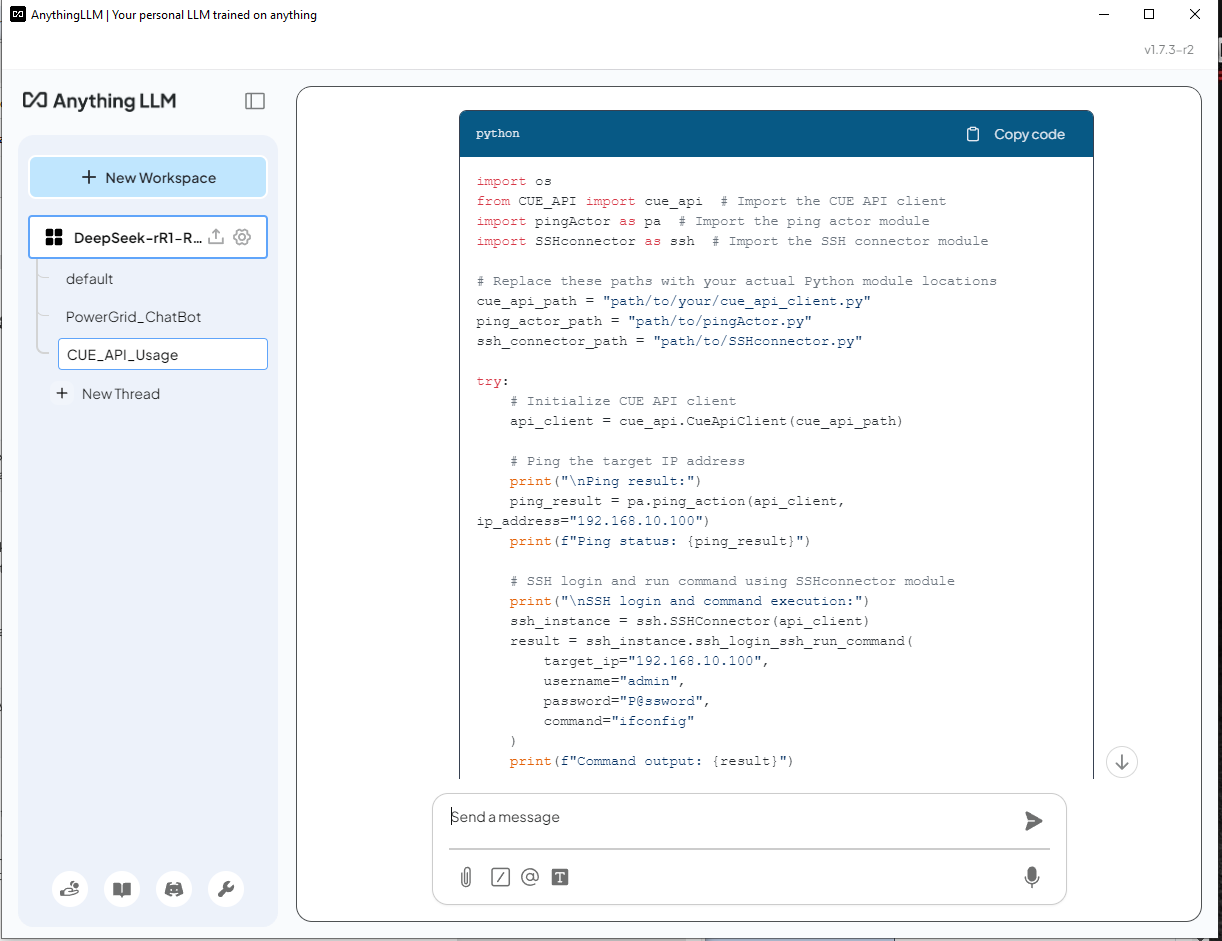
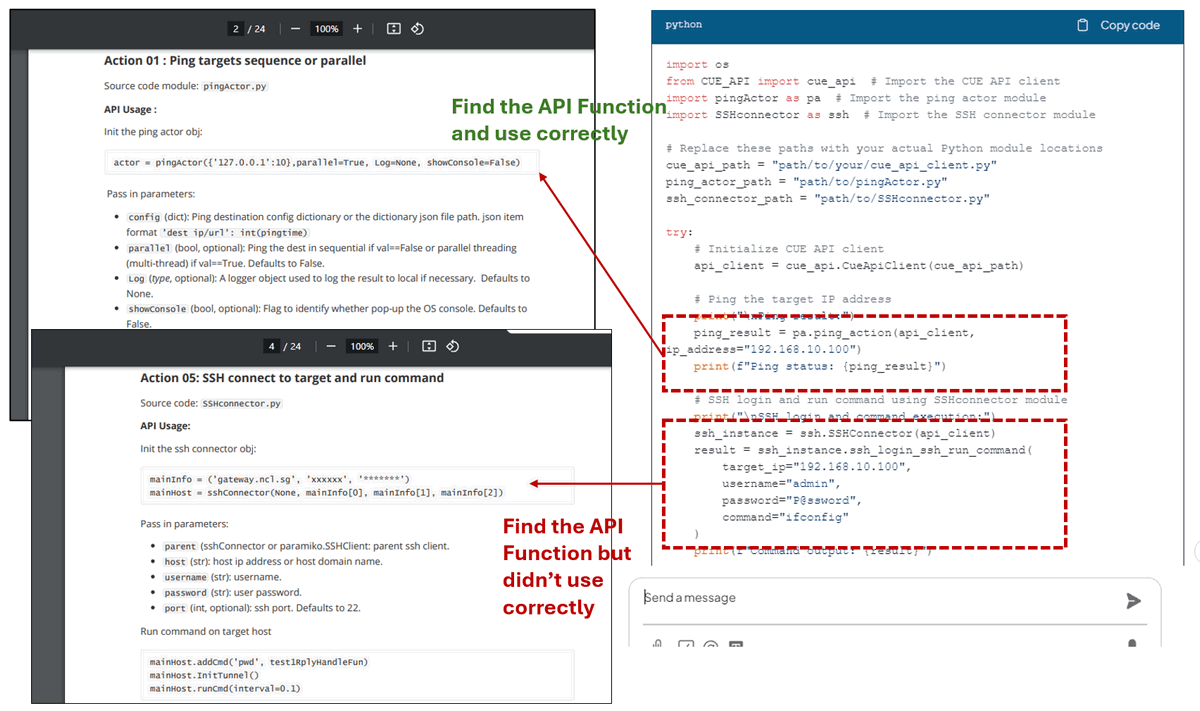
Như chúng ta có thể thấy, DeepSeek-R1 sử dụng mô-đun lib chính xác được cung cấp trong tài liệu API và xây dựng tập lệnh. Đối với mã hành động ping, nó tìm thấy hàm API chính xác từ API_document ở trang 2 và được sử dụng chính xác. Đối với hành động SSH, nó tìm thấy API chính xác từ API_document ở trang 4, nhưng nó không khởi tạo đối tượng trình kết nối một cách chính xác:
Với RAG được bật, DeepSeek-R1 có thể tạo ra các phản hồi dựa trên các tài liệu dành riêng cho miền, làm cho nó chính xác và hữu ích hơn nhiều so với mô hình tiêu chuẩn. Tuy nhiên, việc xem xét mã do AI tạo ra vẫn là cần thiết để đảm bảo tính chính xác. Kết luậnTriển khai DeepSeek-R1 cục bộ với cơ sở kiến thức Tăng Cường Tạo Sinh (RAG) tùy chỉnh cho phép các ứng dụng hỗ trợ AI với chuyên môn dành riêng cho miền nâng cao trong khi vẫn duy trì quyền riêng tư dữ liệu. Bằng cách tận dụng các công cụ như Ollama, nomic-embed-text và AnythingLLM, người dùng có thể xây dựng các chatbot thông minh, trình tạo mã và hệ thống ra quyết định hỗ trợ AI phù hợp với nhu cầu riêng của họ. So sánh giữa các phản hồi LLM tiêu chuẩn và các câu trả lời được tăng cường bằng RAG làm nổi bật những cải tiến đáng kể về độ chính xác và mức độ liên quan khi tích hợp các nguồn kiến thức bên ngoài. Thiết lập này không chỉ nâng cao độ tin cậy của AI mà còn đảm bảo dữ liệu độc quyền vẫn an toàn, khiến nó trở thành một giải pháp mạnh mẽ cho các doanh nghiệp, nhà nghiên cứu và nhà phát triển đang tìm kiếm những hiểu biết sâu sắc dựa trên AI được bản địa hóa.
RELATED1 COMMENTPROGRAMMER HUMOR
SUPPORT USIf you find this article helpful, please consider supporting our work. DONATEABOUTHOW IT WORKSFOLLOW USFEEDBACK |
Great Introduction! Thank you!