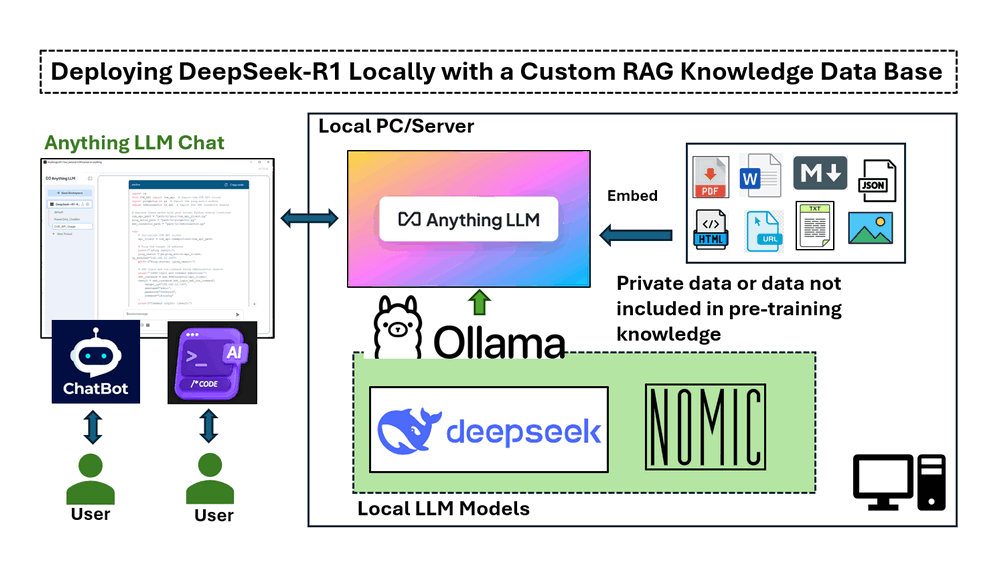
การนำไปใช้งานในบทความนี้ครอบคลุมสี่ส่วนหลัก :
-
การติดตั้งและเรียกใช้ DeepSeek-R1 ในเครื่อง บนเครื่อง Windows ที่มี NVIDIA RTX 3060 GPU
-
การตั้งค่าไปป์ไลน์ RAG โดยใช้ nomic-embed-text สำหรับการดึงข้อความตามเวกเตอร์
-
การปรับใช้ AnythingLLM เพื่อผสานรวมการตอบสนอง AI ตามเอกสาร
-
การทดสอบ DeepSeek-R1 โดยมีและไม่มี RAG แสดงให้เห็นถึงความแม่นยำในการตอบคำถามเฉพาะด้าน
# Version: v_0.0.1
# Created: 2025/02/06
# License: MIT Licenseบทนำ
DeepSeek ซึ่งเป็นบริษัท AI สัญชาติจีน กำลังสร้างความเปลี่ยนแปลงให้กับอุตสาหกรรมด้วยโมเดลภาษาขนาดใหญ่แบบโอเพนซอร์สราคาถูก ซึ่งท้าทายบริษัทยักษ์ใหญ่ด้านเทคโนโลยีของสหรัฐฯ ได้แสดงให้เห็นถึงประสิทธิภาพสูงในด้านคณิตศาสตร์ การเขียนโค้ด การสนทนาภาษาอังกฤษและภาษาจีน โมเดล DeepSeek-R1 เป็นโอเพนซอร์ส (MIT License) บทความนี้จะสำรวจขั้นตอนโดยละเอียดในการปรับใช้โมเดล DeepSeek-R1:7B LLM บนแล็ปท็อป Windows ที่มี NVIDIA RTX 3060 (12GB GPU) เพื่อสร้างแชทบอทที่ขับเคลื่อนด้วย AI ที่ปรับแต่งเอง หรือโปรแกรมสร้างโค้ดโดยใช้ฐานข้อมูลความรู้ Retrieval-Augmented Generation (RAG) และทำการเปรียบเทียบอย่างง่ายระหว่างคำตอบ LLM ปกติและคำตอบ RAG
-
สำหรับแชทบอทบริการลูกค้า AI เราต้องการให้แชทบอทให้ข้อมูลตามเอกสารผลิตภัณฑ์ของบริษัท ทำให้เป็นเครื่องมือที่มีประสิทธิภาพสำหรับการจัดการความรู้ภายในและการสนับสนุนลูกค้า
-
สำหรับโปรแกรมสร้างโค้ด AI เราต้องการให้โปรแกรมช่วยในการพัฒนาซอฟต์แวร์โดยการสร้างส่วนย่อยของโค้ดตาม APIs โปรแกรมที่มีอยู่ หรือนำเข้าฟังก์ชันจากไลบรารีที่กำหนดเอง
ในการนำโครงการนี้ไปใช้งาน เราจะใช้เครื่องมือหลักสี่อย่าง:
-
Ollama : เฟรมเวิร์กน้ำหนักเบาและขยายได้สำหรับการสร้างและเรียกใช้โมเดลภาษาบนเครื่อง
-
DeepSeek-R1 : โมเดลที่ได้รับการฝึกฝนผ่านการเรียนรู้แบบเสริมกำลังขนาดใหญ่ (RL) โดยไม่มีการปรับแต่งอย่างละเอียดภายใต้การดูแล (SFT) เป็นขั้นตอนเบื้องต้น แสดงให้เห็นถึงประสิทธิภาพที่โดดเด่นในการให้เหตุผล
-
nomic-embed-text : โมเดลการฝังข้อความแบบโอเพนซอร์สที่แปลงข้อความเป็นเวกเตอร์ตัวเลข ทำให้คอมพิวเตอร์เข้าใจความหมายเชิงความหมายของข้อความโดยการเปรียบเทียบการแสดงกับข้อความอื่นๆ
-
AnythingLLM : แชทบอท AI แบบโอเพนซอร์สที่ช่วยให้ผู้ใช้แชทกับเอกสาร ได้รับการออกแบบมาเพื่อช่วยให้ธุรกิจและองค์กรต่างๆ ทำให้เอกสารที่เป็นลายลักษณ์อักษรของตนเข้าถึงได้ง่ายขึ้น
แนวทางนี้ช่วยปรับปรุงการตัดสินใจโดยใช้ AI การสนับสนุนทางเทคนิค และการพัฒนาซอฟต์แวร์ อย่างมีนัยสำคัญ โดยทำให้มั่นใจได้ว่าการตอบสนองนั้นมีพื้นฐานมาจากข้อมูลที่น่าเชื่อถือและเฉพาะโดเมน
ความรู้พื้นฐาน
DeepSeek-R1: LLM โอเพนซอร์สประสิทธิภาพสูง
DeepSeek AI กำลังบุกเบิกยุคใหม่ของโมเดลภาษาขนาดใหญ่ (LLMs) ที่ใช้เหตุผลด้วยซีรีส์ DeepSeek-R1 ซึ่งออกแบบมาเพื่อผลักดันขอบเขตของความสามารถในการให้เหตุผลทางคณิตศาสตร์ การเขียนโค้ด และตรรกะ แตกต่างจาก LLMs แบบดั้งเดิมที่พึ่งพาการปรับแต่งอย่างละเอียดภายใต้การดูแล (SFT) อย่างมาก DeepSeek AI ใช้วิธีการเรียนรู้แบบเสริมกำลัง (RL) เป็นอันดับแรก ทำให้โมเดลพัฒนาพฤติกรรมการให้เหตุผลที่ซับซ้อนได้อย่างเป็นธรรมชาติ
วิวัฒนาการของโมเดล DeepSeek-R1
-
DeepSeek-R1-Zero เป็นโมเดลรุ่นแรกที่ได้รับการฝึกฝนอย่างหมดจดผ่านการเรียนรู้แบบเสริมกำลังขนาดใหญ่ (RL) ทำให้สามารถตรวจสอบตนเอง สะท้อน และสร้างสายโซ่ความคิดที่ยาวนาน (CoT) โดยไม่มี SFT อย่างไรก็ตาม โมเดลนี้เผชิญกับความท้าทายต่างๆ เช่น การผสมภาษา ปัญหาด้านความสามารถในการอ่าน และเอาต์พุตซ้ำๆ
-
DeepSeek-R1 ปรับปรุงสิ่งนี้โดยการรวมข้อมูล cold-start ก่อนการฝึก RL ส่งผลให้โมเดลมีความละเอียดและสอดคล้องกับมนุษย์มากขึ้น โดยมีประสิทธิภาพเทียบเท่ากับ OpenAI-o1 ในเกณฑ์มาตรฐานการให้เหตุผลต่างๆ
ลิงก์อ้างอิง : https://api-docs.deepseek.com/
ทำความเข้าใจ Retrieval-Augmented Generation (RAG)
Retrieval-augmented generation เป็นเทคนิคสำหรับการปรับปรุงความแม่นยำและความน่าเชื่อถือของโมเดล AI เชิงสร้างสรรค์ด้วยข้อมูลจากแหล่งข้อมูลเฉพาะและเกี่ยวข้อง RAG ช่วยเพิ่มประสิทธิภาพโมเดล AI เชิงสร้างสรรค์โดยการดึงข้อมูลภายนอกก่อนสร้างการตอบสนอง นำไปสู่คำตอบที่แม่นยำ ทันสมัย และคำนึงถึงบริบทมากขึ้น
ขั้นตอนการทำงานของ RAS แสดงไว้ด้านล่าง:
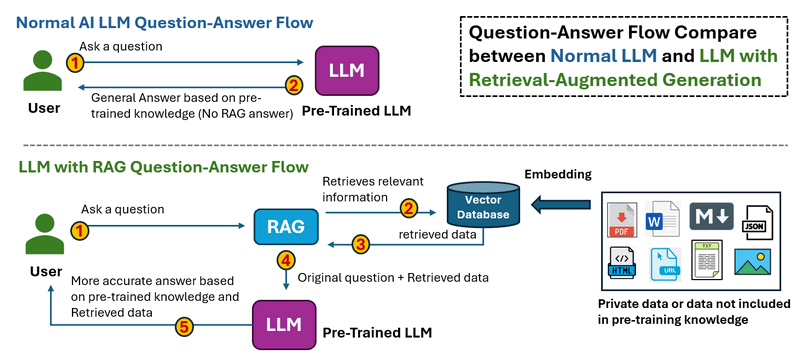
-
ในขั้นตอนการถาม-ตอบ LLM ปกติ เมื่อผู้ใช้ถามคำถาม Thee LLM จะประมวลผลอินพุตและสร้างคำตอบโดยอิงจากความรู้ที่ได้รับการฝึกฝนมาล่วงหน้าเท่านั้น ไม่มีการดึงข้อมูลภายนอก ซึ่งหมายความว่าข้อมูลที่ล้าสมัยหรือขาดหายไปไม่สามารถแก้ไขได้
-
ในLLM พร้อมขั้นตอนการถาม-ตอบ RAG เมื่อผู้ใช้ถามคำถาม ระบบจะดึงข้อมูลที่เกี่ยวข้องจากแหล่งภายนอก (ฐานข้อมูล เอกสาร APIs หรือเว็บ) ก่อน ข้อมูลที่ดึงมาจะถูกป้อนเข้าสู่ LLM พร้อมกับคำถามเดิม จากนั้น LLM จะสร้างคำตอบโดยอิงจากทั้งความรู้ที่ได้รับการฝึกฝนมาล่วงหน้าและข้อมูลที่ดึงมา นำไปสู่การตอบสนองที่แม่นยำและทันสมัยยิ่งขึ้น
ลิงก์อ้างอิง : https://blogs.nvidia.com/blog/what-is-retrieval-augmented-generation/
ขั้นตอนที่ 1 : ปรับใช้โมเดล DeepSeek-R1 บนเครื่องของคุณ
ในการตั้งค่าโมเดล DeepSeek-R1 ในเครื่องของคุณ ขั้นแรกคุณต้องติดตั้ง Ollama ซึ่งเป็นเฟรมเวิร์กน้ำหนักเบาและขยายได้สำหรับการรันโมเดลภาษาขนาดใหญ่บนเครื่องของคุณ จากนั้น คุณจะต้องดาวน์โหลดโมเดล DeepSeek-R1 ที่เหมาะสมตามข้อกำหนดของฮาร์ดแวร์ของคุณ
1.1 ติดตั้ง Ollama
ดาวน์โหลด Ollama จากเว็บไซต์ทางการ: https://ollama.com/download และเลือกแพ็กเกจการติดตั้งสำหรับระบบปฏิบัติการของคุณ:
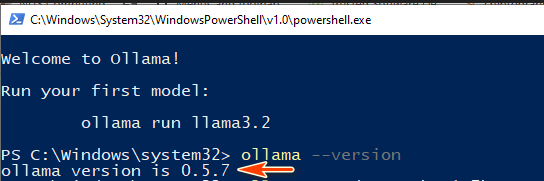
เมื่อการติดตั้งเสร็จสมบูรณ์ ให้ตรวจสอบว่า Ollama ได้รับการติดตั้งอย่างถูกต้องโดยรันคำสั่งต่อไปนี้ในเทอร์มินัล:
ollama --version
หากหมายเลขเวอร์ชันปรากฏขึ้น แสดงว่า Ollama พร้อมใช้งาน:
ต่อไป ให้เริ่มบริการ Ollama โดยรัน:
ollama serve
1.2 เลือกโมเดล DeepSeek-R1 ที่เหมาะสม
DeepSeek-R1 มีโมเดลให้เลือกตั้งแต่รุ่นขนาดกะทัดรัด 1.5 พันล้านพารามิเตอร์ ไปจนถึงโมเดลขนาดใหญ่ 671 พันล้านพารามิเตอร์ ขนาดโมเดลที่คุณเลือกควรตรงกับหน่วยความจำ GPU (VRAM) และทรัพยากรระบบของคุณ ใน Ollama web ให้เลือก models จากนั้นค้นหา deepseek ดังที่แสดงด้านล่าง:
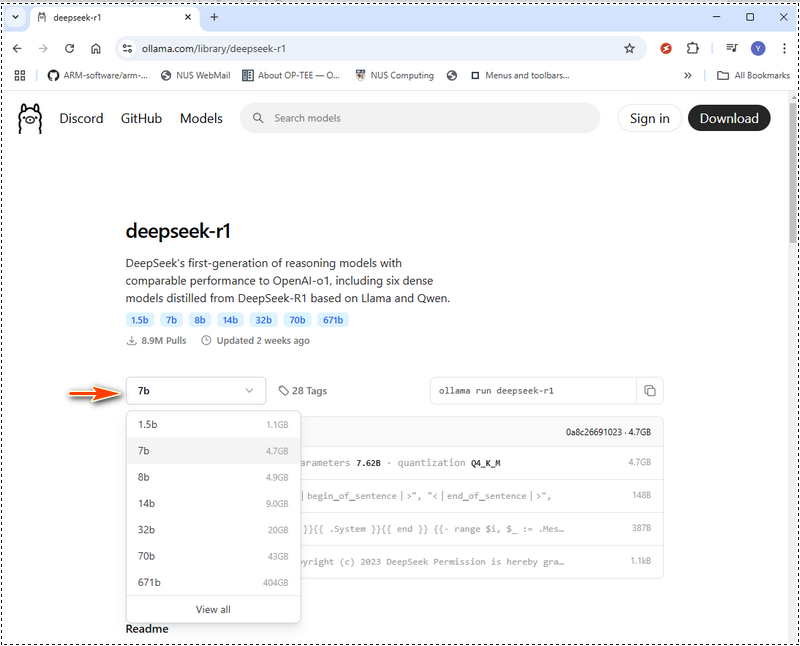
ด้านล่างนี้คือตารางข้อกำหนดของฮาร์ดแวร์เพื่อช่วยคุณตัดสินใจว่าจะปรับใช้โมเดลใด หากฮาร์ดแวร์ของคุณต่ำกว่าสเปคที่แนะนำ คุณยังสามารถรันโมเดลที่ใหญ่กว่าได้โดยใช้เครื่องมือเพิ่มประสิทธิภาพฮาร์ดแวร์ เช่น LMStudio (https://lmstudio.ai/) แต่จะทำให้เวลาในการประมวลผลเพิ่มขึ้น ข้อกำหนดของฮาร์ดแวร์ DeepSeek-R1 :
| ชื่อโมดูล | ระดับประเภทโมเดล | GPU VRAM | CPU | RAM | ดิสก์ | ||
|---|---|---|---|---|---|---|---|
| deepseek-r1:1.5b | เข้าถึงได้ | ไม่จำเป็นต้องใช้ GPU หรือ VRAM เฉพาะ | CPU ที่มีอายุไม่เกิน 10 ปี | 8 GB | 1.1 GB | ||
| deepseek-r1:7b | น้ำหนักเบา | 8 GB ของ VRAM | CPU เดี่ยว เช่น i5 | 8 GB | 4.7 GB | ||
| deepseek-r1:8b | น้ำหนักเบา | 8 GB ของ VRAM | CPU เดี่ยว เช่น i5, i7 | 8 GB | 4.9 GB | ||
| deepseek-r1:14b | ระดับกลาง | 12 - 16 GB ของ VRAM | CPU เดี่ยว (i7/i9) หรือ CPU คู่ (Xeon Silver 4114 x2) | 16-32 GB | 9.0 GB | ||
| deepseek-r1:32b | ระดับกลาง | 24 GB ของ VRAM | CPU คู่ (Xeon Silver 4114 x2) | 32 - 64 GB |
สำหรับโมเดล 671b ต้องใช้ VRAM ประมาณ 480 GB การตั้งค่าแบบ Multi-GPU เป็นสิ่งจำเป็น โดยมีการกำหนดค่าดังนี้:
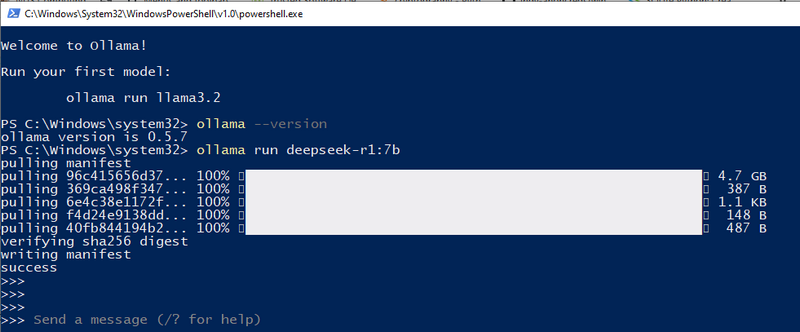
อ้างอิง: 1.3 ดาวน์โหลดและรัน DeepSeek-R1 สำหรับการกำหนดค่าในเครื่องของฉัน ฉันใช้ 3060GPU(12GB) ดังนั้นฉันจึงสามารถลองใช้ 7b ได้ เราสามารถใช้ ollama run deepseek-r1:7b
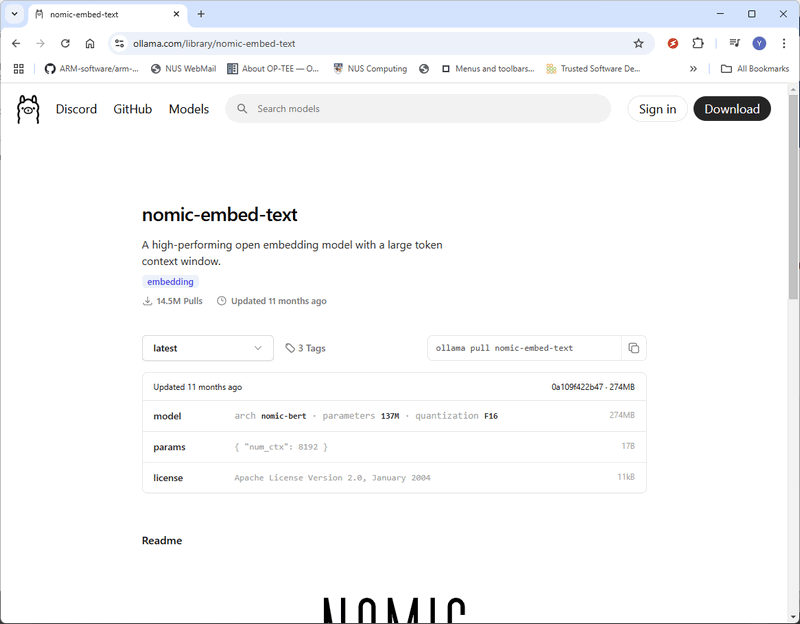
ขณะนี้ DeepSeek-R1 ได้รับการติดตั้งบนเครื่องของคุณเรียบร้อยแล้ว และคุณสามารถเริ่มถามคำถาม AI ได้โดยตรงจากเทอร์มินัล ขั้นตอนที่ 2: ติดตั้ง nomic-embed-textในการสร้างฐานความรู้ RAG (Retrieval-Augmented Generation) เราต้องใช้ nomic-embed-text ซึ่งแปลงข้อมูล (เช่น ไฟล์ PDF หรือข้อความ) เป็นเวกเตอร์ representations เวกเตอร์ embeddings เหล่านี้ช่วยให้โมเดล AI เข้าใจความสัมพันธ์เชิงความหมายระหว่างข้อความต่างๆ ซึ่งช่วยปรับปรุงความแม่นยำในการค้นหาและการดึงข้อมูล 2.1 ดาวน์โหลด nomic-embed-text เยี่ยมชมหน้าอย่างเป็นทางการ: https://ollama.com/library/nomic-embed-text และดาวน์โหลดเวอร์ชันล่าสุดตามที่แสดงด้านล่าง:
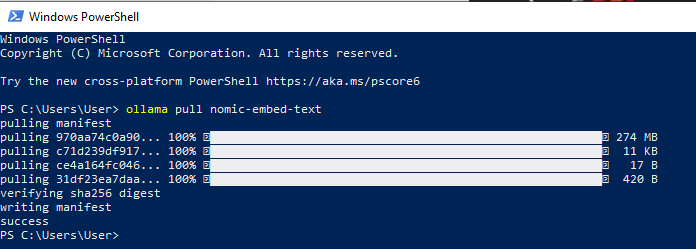
คุณยังสามารถติดตั้ง nomic-embed-text ได้โดยตรงโดยใช้คำสั่ง Ollama pull: ollama pull nomic-embed-text
ขั้นตอนที่ 3: ติดตั้ง AnythingLLM และปรับใช้ RAGในการตั้งค่า ระบบ RAG (Retrieval-Augmented Generation) เราจะใช้ AnythingLLM ซึ่งเป็น AI chatbot แบบโอเพนซอร์สที่ช่วยให้สามารถโต้ตอบกับเอกสารได้อย่างราบรื่น 3.1 ดาวน์โหลดและติดตั้ง AnythingLLM เยี่ยมชมหน้าดาวน์โหลด AnythingLLM อย่างเป็นทางการ: https://anythingllm.com/desktop และดาวน์โหลดตัวติดตั้งที่เหมาะสมสำหรับระบบปฏิบัติการของคุณ
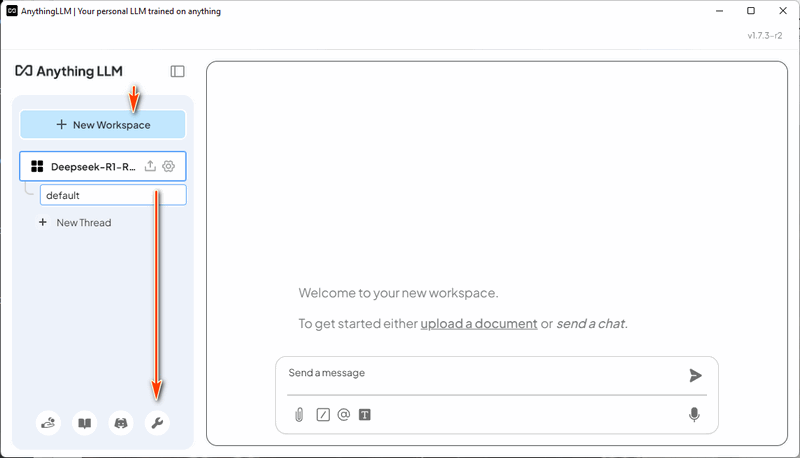
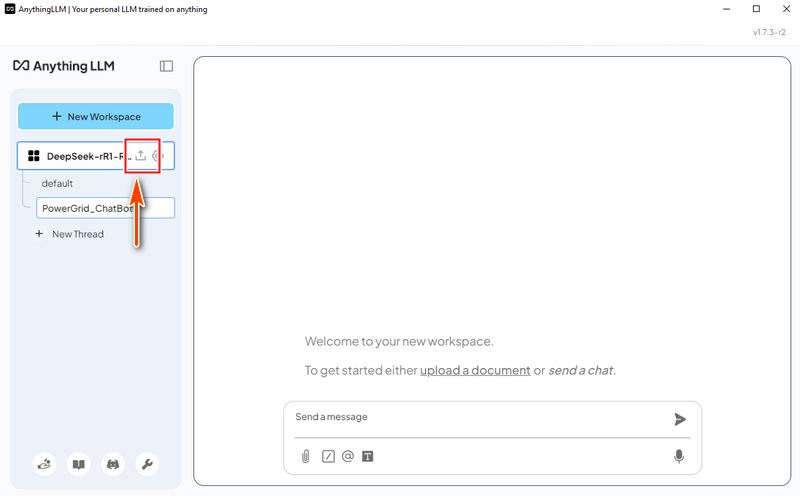
3.2 สร้าง Workspace หลังจากติดตั้งและรัน AnythingLLM ให้สร้าง workspace ใหม่ชื่อ "DeepSeek-R1-RAG" จากนั้นคลิกที่ไอคอน "Open Settings" สำหรับ workspace ตามที่แสดงด้านล่าง:
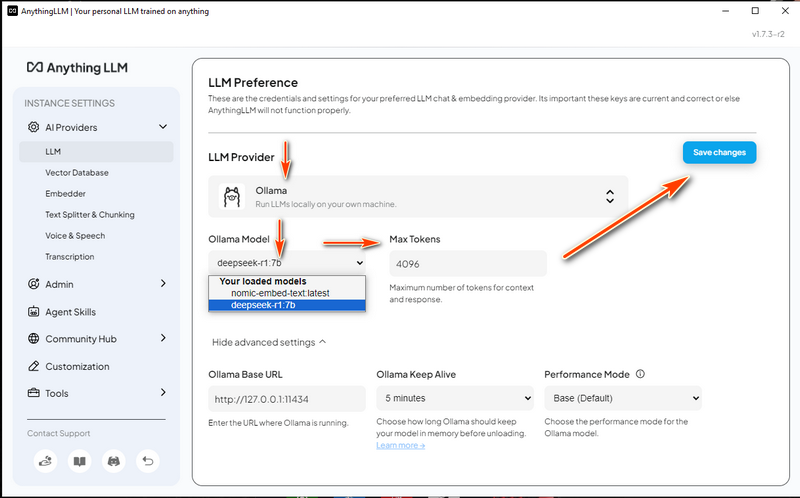
3.3 กำหนดค่า LLM Settings
3.4 กำหนดค่า Vector Database
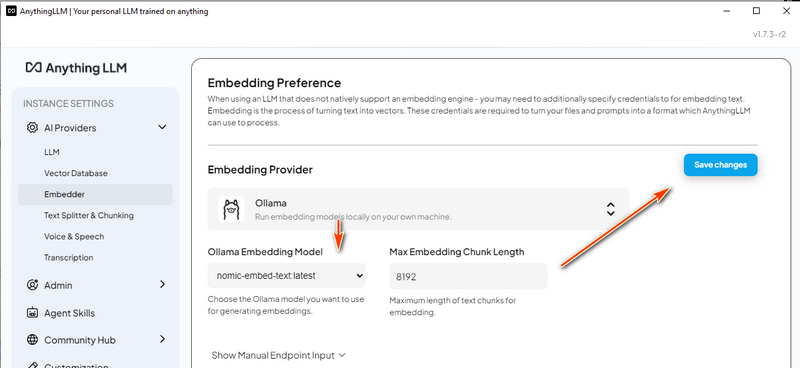
3.5 กำหนดค่า Embedding Model
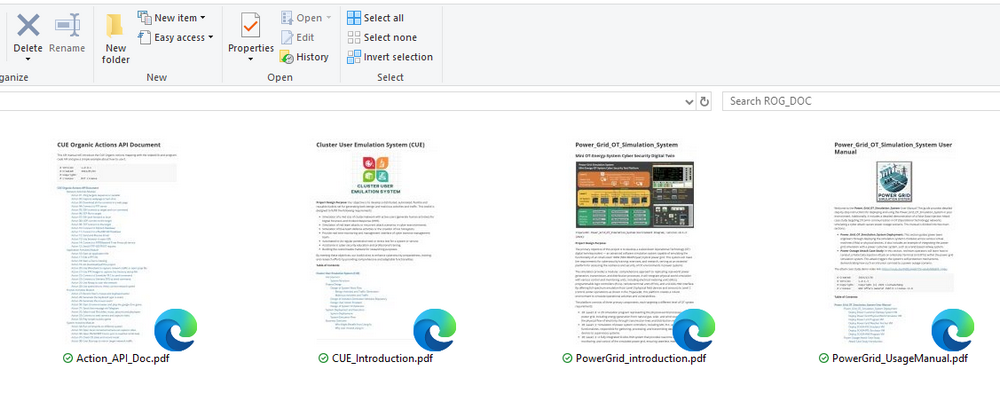
ขั้นตอนที่ 4: โหลดข้อมูล RAG และเริ่มการทดสอบตอนนี้เราได้ทำการตั้งค่าเสร็จสมบูรณ์แล้ว เราสามารถโหลดเอกสารลงในระบบ RAG และทดสอบแชทบอท DeepSeek-R1 ได้ 4.1 เตรียมฐานความรู้ เราจะใช้เอกสาร PDFสี่ฉบับเพื่อสร้างฐานความรู้ของ AI:
เอกสารระบบจำลองโครงข่ายไฟฟ้า
เอกสารระบบจำลองการกระทำของผู้ใช้คลัสเตอร์ (CUE)
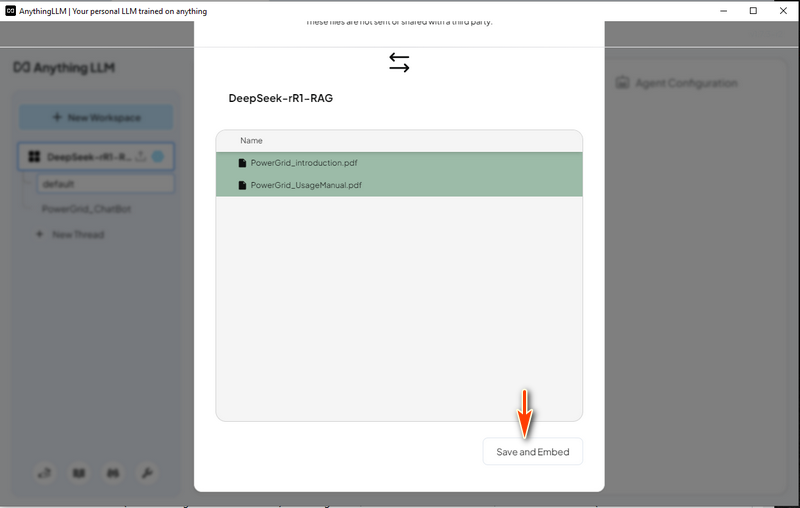
4.2 โหลดข้อมูลระบบโครงข่ายไฟฟ้า ใน AnythingLLM สร้างเธรด "Power Grid Chat Bot" แล้วคลิกไอคอนอัปโหลด:
จากนั้นเลือก "Save and Embed" ตามที่แสดงด้านล่าง หลังจากที่ความคืบหน้าเสร็จสิ้น LLM พร้อม RAG ก็พร้อมใช้งาน
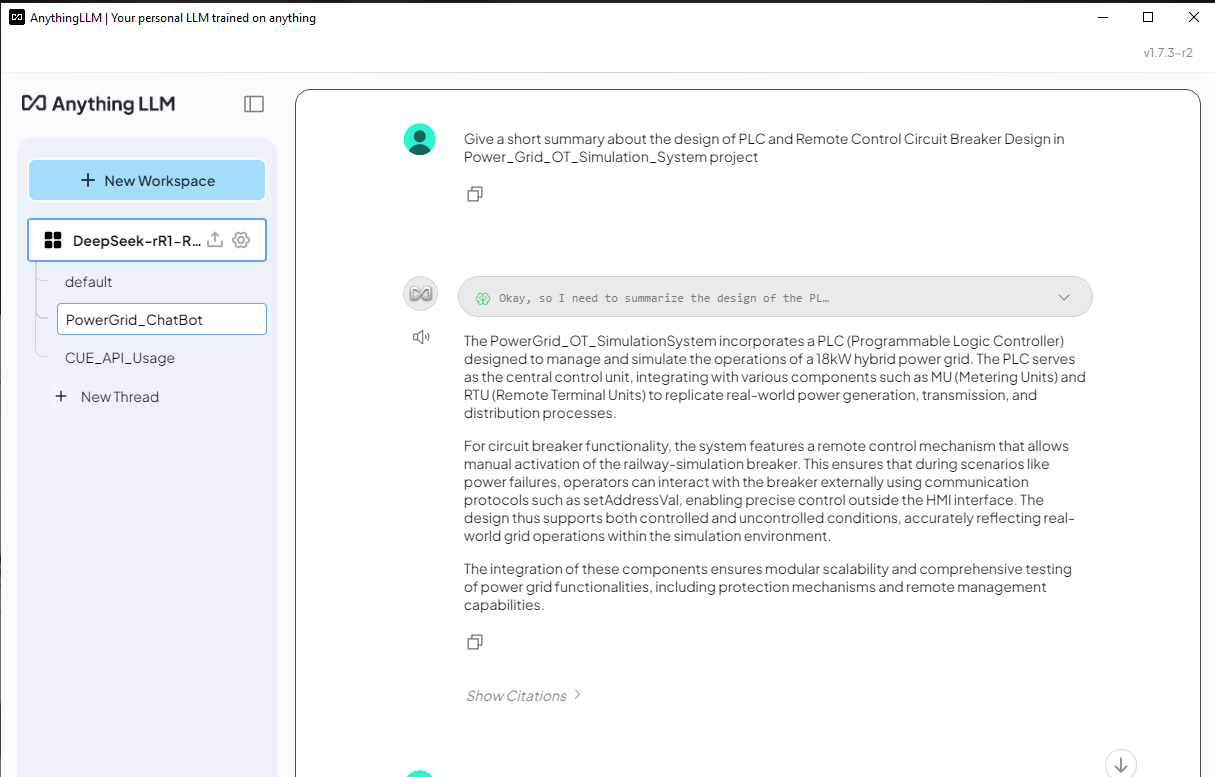
4.3 ทดสอบ DeepSeek-R1 ChatBot ด้วยข้อมูล Power Grid RAG ตอนนี้เราสามารถลองถามคำถาม DeepSeek-R1 ที่เกี่ยวข้องกับระบบจำลองโครงข่ายไฟฟ้า และเปรียบเทียบผลลัพธ์ระหว่างคำตอบที่มีและไม่มี RAG คำถาม: ให้สรุปสั้นๆ เกี่ยวกับการออกแบบ PLC และการออกแบบตัวตัดวงจรรีโมทคอนโทรลในโครงการ Power_Grid_OT_Simulation_System
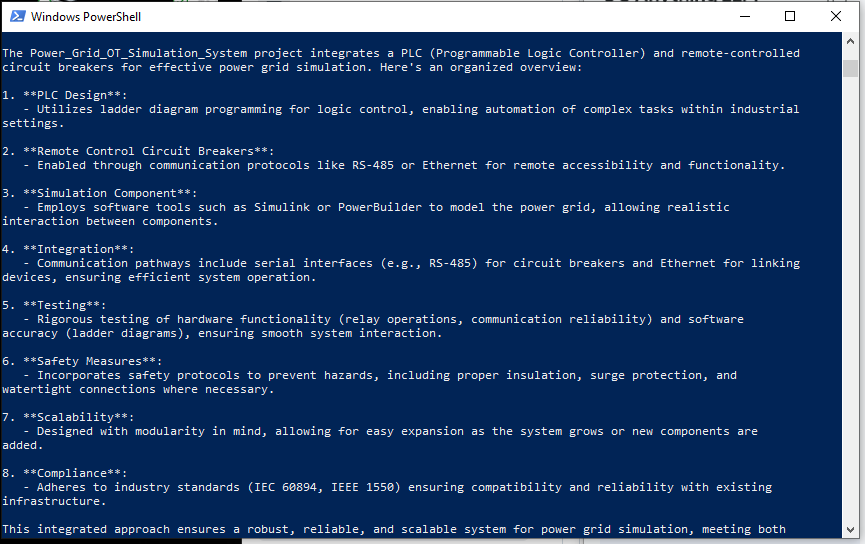
คำตอบ DeepSeek-R1 (ไม่มี RAG)- สำหรับ DeepSeek-R1 ที่ไม่มี RAG จะแสดงรายการคำตอบทั่วไปมากตามที่แสดงด้านล่าง และการตอบสนองไม่มีความสัมพันธ์กับโครงการ Power_Grid_OT_Simulation_System:
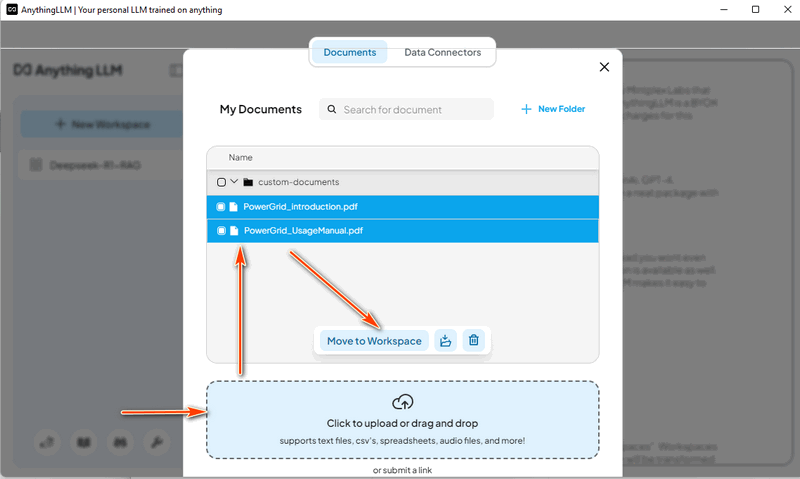
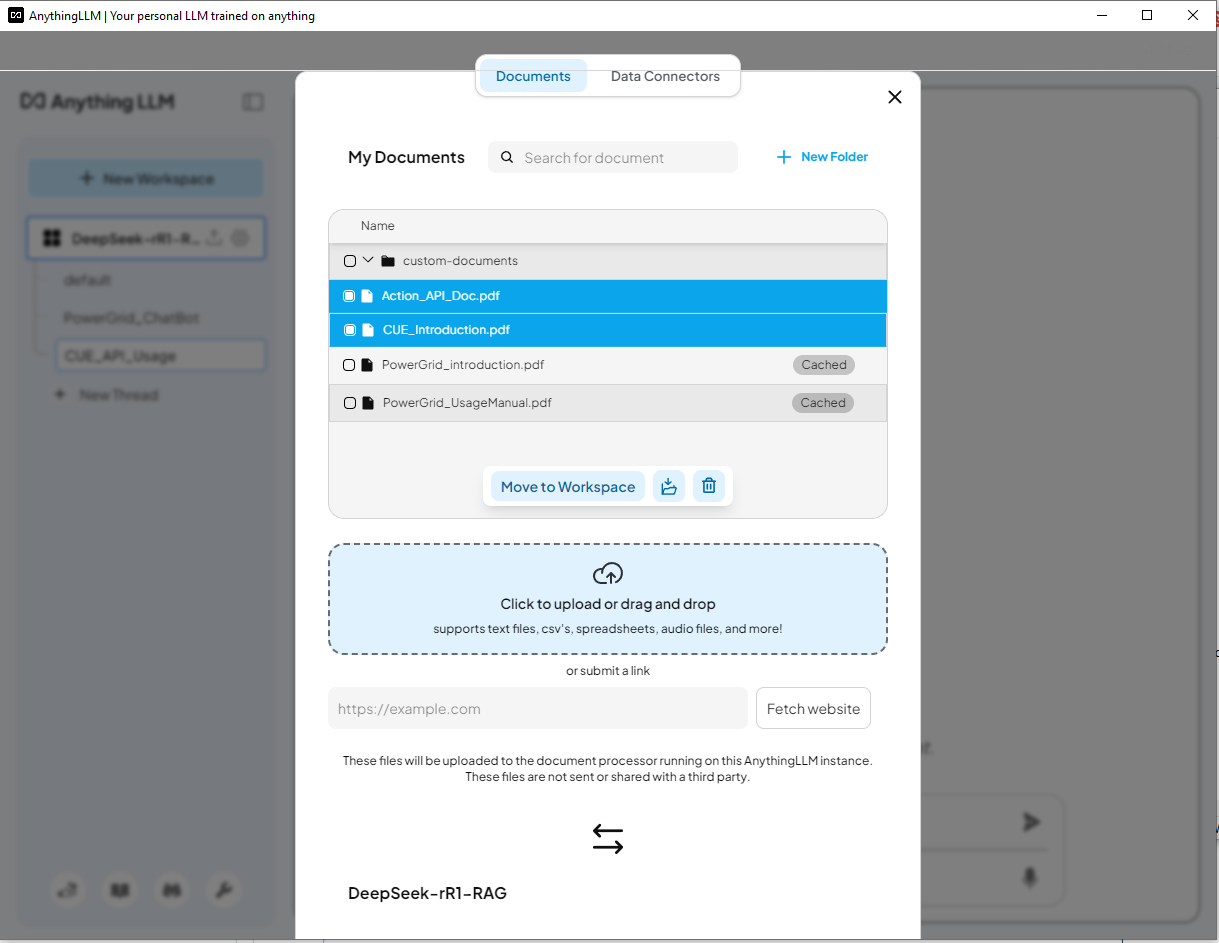
4.4 โหลดข้อมูลโปรเจ็กต์ Cluster User Action Emulator คราวนี้เราจะนำเอกสาร power grid ออกและโหลดเอกสารแนะนำโปรเจ็กต์ Cluster User Action Emulator
4.5 ทดสอบ DeepSeek-R1 ChatBot ด้วยข้อมูล CUE ตอนนี้เราสามารถลองถามคำถามกับ DeepSeek-R1 ที่เกี่ยวข้องกับการสร้างสคริปต์ Python ด้วยฟังก์ชัน lib ในระบบจำลองการทำงานของผู้ใช้คลัสเตอร์ คำถาม: Help create a python script/function uses the cluster user emulator(CUE) function API to ping an IP 192.168.10.100 and ssh login to the server with (username: admin, password: P@ssword) to run a command "ifconfig"
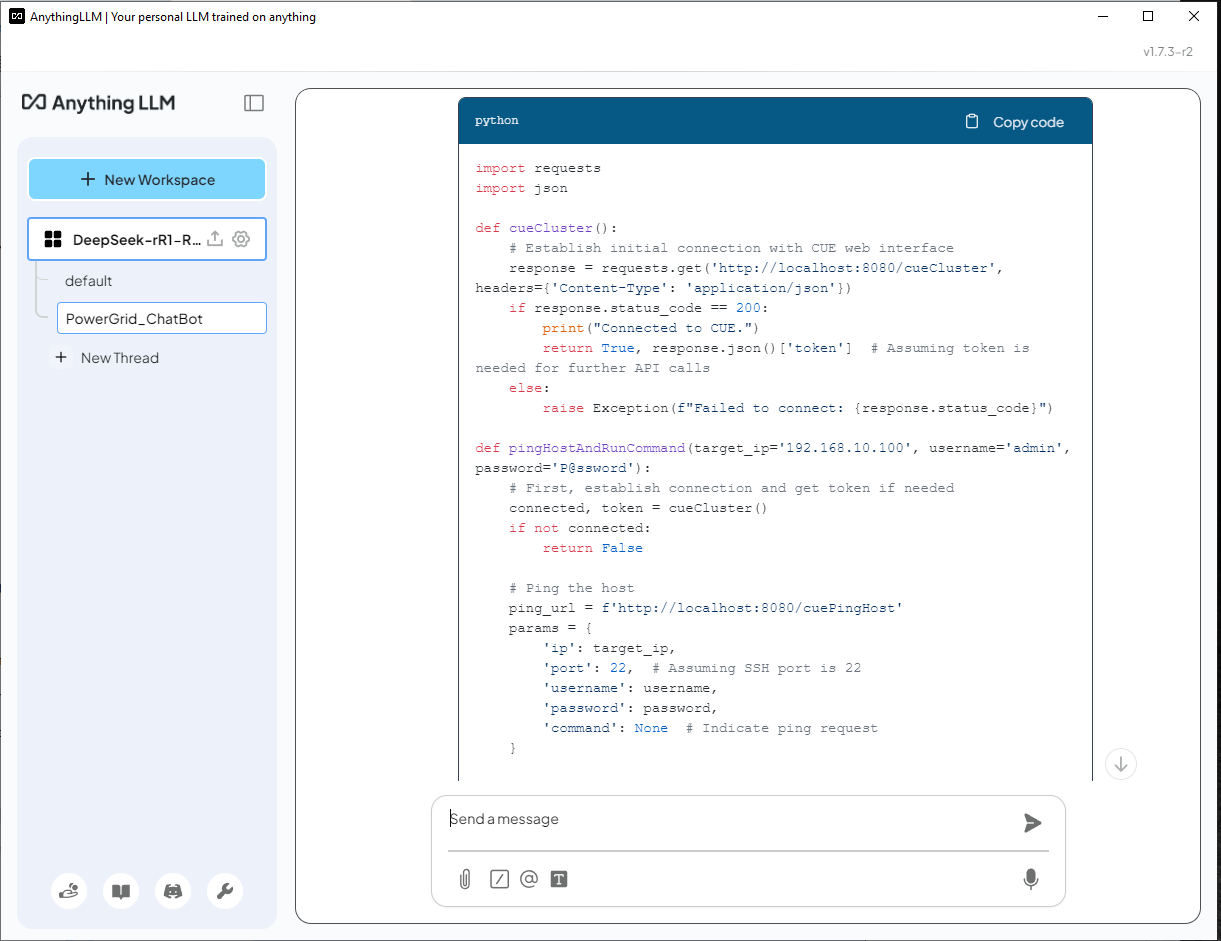
DeepSeek-R1 (Without RAG) ตอบ - AI ไม่รู้จัก CUE และสร้างโซลูชันอย่างไม่ถูกต้องโดยใช้ไลบรารี
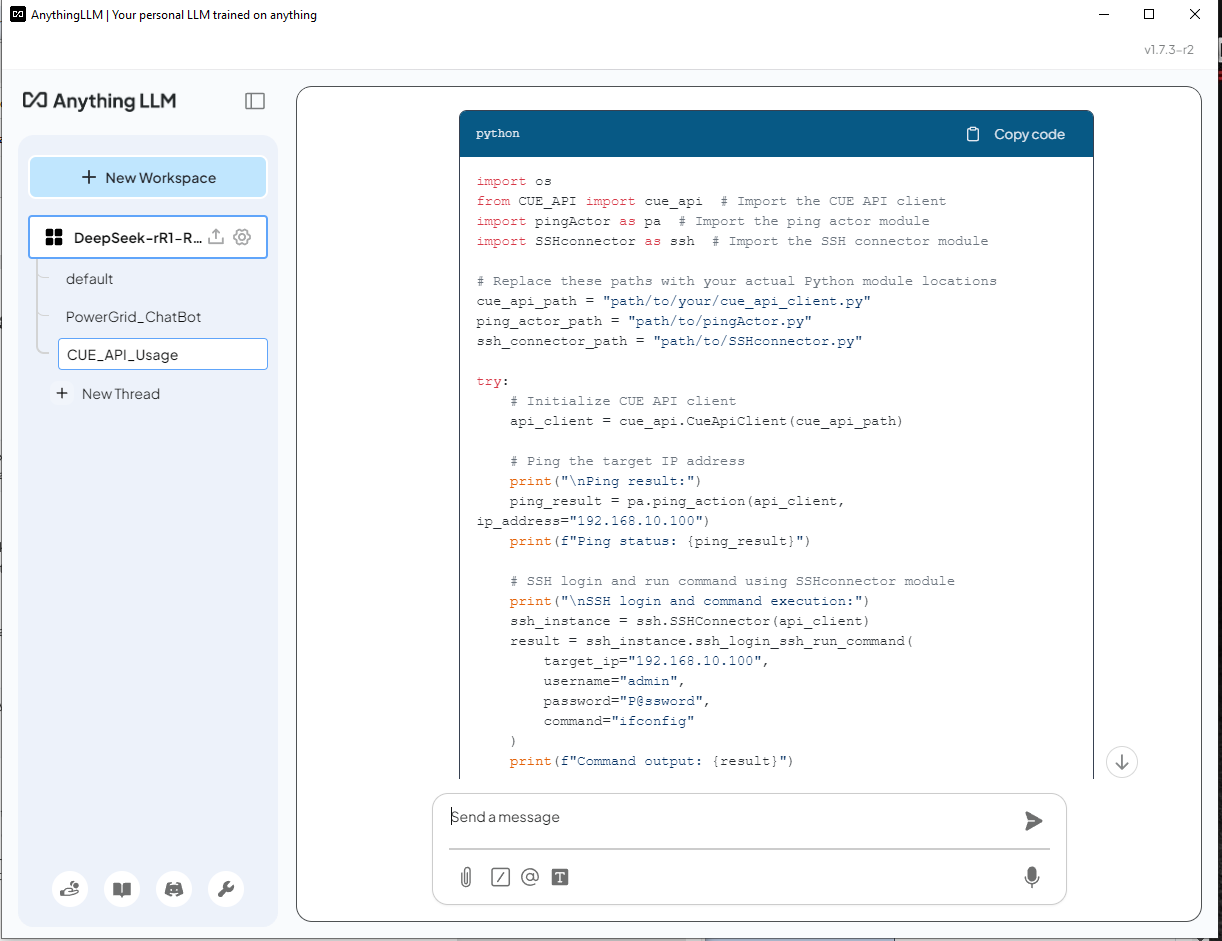
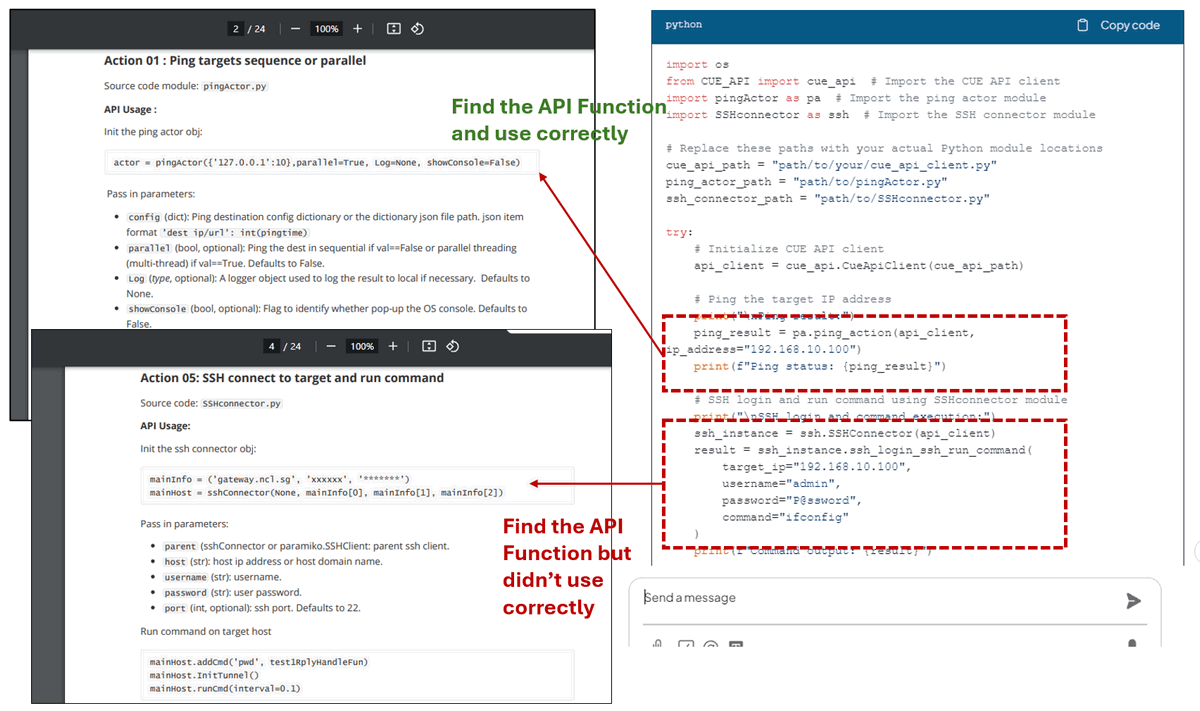
ดังที่เราเห็น DeepSeek-R1 ใช้โมดูล lib ที่ถูกต้องซึ่งมีให้ในเอกสาร API และสร้างสคริปต์ สำหรับโค้ดการทำงาน ping นั้นจะค้นหาฟังก์ชัน API ที่ถูกต้องจาก API_document ในหน้า 2 และใช้งานอย่างถูกต้อง สำหรับการทำงาน SSH นั้นจะค้นหา API ที่ถูกต้องจาก API_document ในหน้า 4 แต่ไม่ได้เริ่มต้นอ็อบเจ็กต์ตัวเชื่อมต่ออย่างถูกต้อง:
เมื่อเปิดใช้งาน RAG แล้ว DeepSeek-R1 สามารถสร้างการตอบสนองตามเอกสารเฉพาะโดเมน ทำให้มีความถูกต้องและมีประโยชน์มากกว่าโมเดลมาตรฐาน อย่างไรก็ตาม การตรวจสอบโค้ดที่สร้างโดย AI ยังคงมีความจำเป็นเพื่อให้แน่ใจว่าถูกต้อง สรุปการปรับใช้ DeepSeek-R1 ในเครื่องด้วยฐานความรู้ Retrieval-Augmented Generation (RAG) ที่กำหนดเอง ช่วยให้แอปพลิเคชันที่ขับเคลื่อนด้วย AI มีความเชี่ยวชาญเฉพาะโดเมนที่ได้รับการปรับปรุง ในขณะที่ยังคงรักษาความเป็นส่วนตัวของข้อมูล การใช้ประโยชน์จากเครื่องมือต่างๆ เช่น Ollama, nomic-embed-text และ AnythingLLM ผู้ใช้สามารถสร้างแชทบอทอัจฉริยะ ตัวสร้างโค้ด และระบบสนับสนุนการตัดสินใจด้วย AI ที่ปรับให้เหมาะกับความต้องการเฉพาะของตน การเปรียบเทียบระหว่างการตอบสนองของ LLM มาตรฐานและการตอบสนองที่ได้รับการปรับปรุงด้วย RAG เน้นถึงการปรับปรุงที่สำคัญในด้านความถูกต้องและความเกี่ยวข้องเมื่อรวมแหล่งความรู้ภายนอก การตั้งค่านี้ไม่เพียงแต่ปรับปรุงความน่าเชื่อถือของ AI เท่านั้น แต่ยังรับประกันว่าข้อมูลที่เป็นกรรมสิทธิ์จะยังคงปลอดภัย ทำให้เป็นโซลูชันที่มีประสิทธิภาพสำหรับธุรกิจ นักวิจัย และนักพัฒนาที่ต้องการข้อมูลเชิงลึกที่ขับเคลื่อนด้วย AI ในพื้นที่
RELATED1 COMMENTPROGRAMMER HUMOR
SUPPORT USIf you find this article helpful, please consider supporting our work. DONATEABOUTHOW IT WORKSFOLLOW USFEEDBACK |

Great Introduction! Thank you!