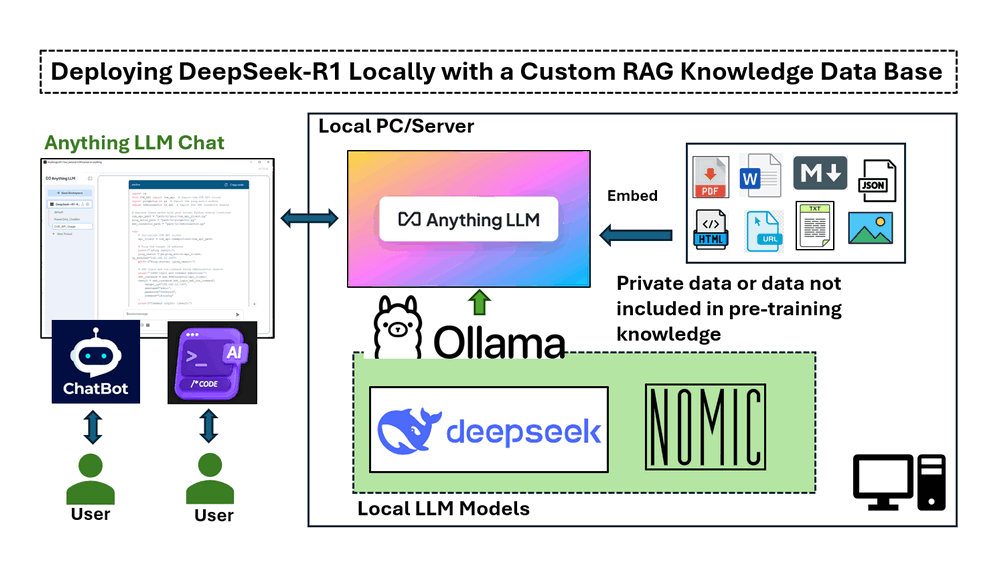
本文中的实现涵盖四个主要部分:
-
在本地安装和运行 DeepSeek-R1 在配备 NVIDIA RTX 3060 GPU 的 Windows 机器上。
-
设置 RAG 管道 使用 nomic-embed-text 进行基于向量的文本检索。
-
部署 AnythingLLM 以集成基于文档的 AI 响应。
-
测试带有和不带有 RAG 的 DeepSeek-R1,展示其在响应特定领域查询方面的准确性。
# Version: v_0.0.1
# Created: 2025/02/06
# License: MIT License介绍
DeepSeek 是一家中国 AI 公司,正以其低成本、开源的大型语言模型颠覆该行业,挑战美国科技巨头。它在数学、编码、英语和中文对话方面表现出高性能。DeepSeek-R1 模型是开源的(MIT License)。本文将探讨在配备 NVIDIA RTX 3060 (12GB GPU) 的 Windows 笔记本电脑上部署 DeepSeek-R1:7B LLM 模型的详细步骤,以创建定制的 AI 驱动的聊天机器人或使用知识库检索增强生成 (RAG) 的程序代码生成器,并对普通 LLM 答案和 RAG 答案进行简单比较。
-
对于AI 客户服务聊天机器人,我们希望它基于公司产品文档提供信息,使其成为内部知识管理和客户支持的强大工具。
-
对于AI 程序代码生成器,我们希望它通过生成基于现有程序 API 的代码片段或从定制库导入函数来协助软件开发。
为了实现这个项目,我们将使用四个关键工具:
-
Ollama : 一个轻量级、可扩展的框架,用于在本地机器上构建和运行语言模型。
-
DeepSeek-R1 : 一种通过大规模强化学习 (RL) 训练的模型,没有监督微调 (SFT) 作为初步步骤,在推理方面表现出卓越的性能。
-
nomic-embed-text : 一种开源文本嵌入模型,可将文本转换为数字向量,使计算机能够通过比较其表示形式与其他表示形式来理解文本的语义含义。
-
AnythingLLM : 一种开源 AI 聊天机器人,允许用户与文档聊天。它旨在帮助企业和组织使其书面文档更易于访问。
这种方法通过确保响应基于可靠的、特定领域的信息,从而显著改善AI 辅助的决策、技术支持和软件开发。
背景知识
DeepSeek-R1:高性能开源 LLM
DeepSeek AI 正在通过其 DeepSeek-R1 系列引领基于推理的大型语言模型 (LLM) 的新时代,该系列旨在突破数学、编码和逻辑推理能力的界限。与严重依赖监督微调 (SFT) 的传统 LLM 不同,DeepSeek AI 采用强化学习 (RL) 优先的方法,使模型能够自然地发展复杂的推理行为。
DeepSeek-R1 模型的演变
-
DeepSeek-R1-Zero 是第一个完全通过大规模强化学习 (RL) 训练的生成模型,使其能够自我验证、反思和生成长链思维 (CoT),而无需 SFT。但是,它面临着诸如语言混合、可读性问题和重复输出等挑战。
-
DeepSeek-R1 通过在 RL 训练之前合并冷启动数据对此进行了改进,从而产生了更精细和更符合人类的模型,其性能与 OpenAI-o1 在各种推理基准测试中相当。
参考链接:https://api-docs.deepseek.com/
了解检索增强生成 (RAG)
检索增强生成是一种通过来自特定和相关数据源的信息来提高生成式 AI 模型的准确性和可靠性的技术。RAG 通过在生成响应之前检索外部数据来增强生成式 AI 模型,从而产生更准确、最新和具有上下文意识的答案。
RAS 的工作流程如下所示:
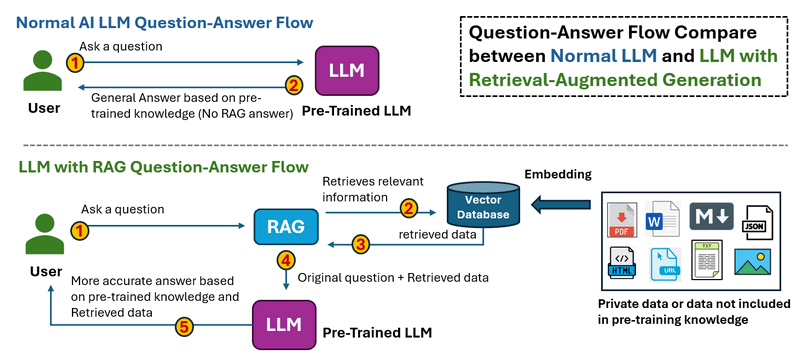
-
在普通 LLM 问答流程中,当用户提出问题时。Thee LLM 处理输入并生成答案仅基于其预先训练的知识。没有外部数据检索,这意味着无法更正过时或缺失的信息。
-
在带有 RAG 的 LLM 问答流程中,当用户提出问题时。系统首先从外部来源(数据库、文档、API 或 Web)检索相关信息。检索到的数据与原始问题一起馈送到 LLM 中,然后 LLM 基于预先训练的知识和检索到的数据生成答案,从而产生更准确和最新的响应。
参考链接:https://blogs.nvidia.com/blog/what-is-retrieval-augmented-generation/
步骤 1:在您的本地机器上部署 DeepSeek-R1 模型
要在本地设置 DeepSeek-R1 模型,您首先需要安装 Ollama,这是一个轻量级、可扩展的框架,用于在您的机器上运行大型语言模型。然后,您将根据您的硬件规格下载适当的 DeepSeek-R1 模型。
1.1 安装 Ollama
从官方网站下载 Ollama:https://ollama.com/download,并选择适用于您操作系统的安装包:
安装完成后,通过在终端中运行以下命令来验证 Ollama 是否已正确安装:
ollama --version
如果显示版本号,则表示 Ollama 已准备好使用:
接下来,通过运行以下命令启动 Ollama 服务:
ollama serve
1.2 选择合适的 DeepSeek-R1 模型
DeepSeek-R1 提供了从紧凑的 15 亿参数版本到庞大的 6710 亿参数模型的各种模型。您选择的模型大小应与您的 GPU 内存 (VRAM) 和系统资源相匹配。在 Ollama web 中,选择模型然后搜索 deepseek,如下所示:
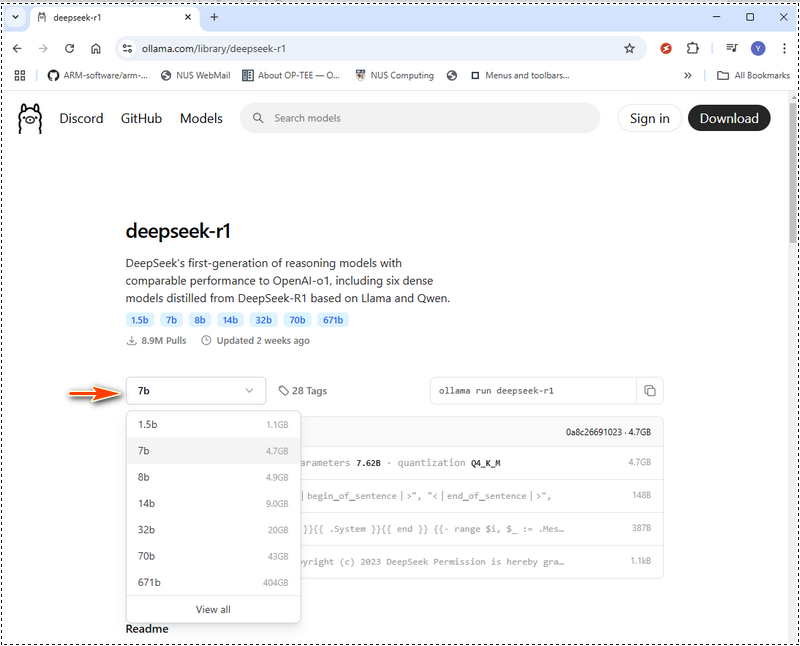
下面是一个硬件要求表,可帮助您决定要部署哪个模型。如果您的硬件低于推荐规格,您仍然可以使用 LMStudio 等硬件优化工具运行更大的模型(https://lmstudio.ai/),但这会增加处理时间。DeepSeek-R1 硬件要求:
| 模块名称 | 模型类型级别 | GPU VRAM | CPU | RAM | 磁盘 |
|---|---|---|---|---|---|
| deepseek-r1:1.5b | 可访问 | 不需要专用 GPU 或 VRAM | CPU 不超过 10 年 | 8 GB | 1.1 GB |
| deepseek-r1:7b | 轻量级 | 8 GB 的 VRAM | 单 CPU,如 i5 | 8 GB | 4.7 GB |
| deepseek-r1:8b | 轻量级 | 8 GB 的 VRAM | 单 CPU,如 i5、i7 | 8 GB | 4.9 GB |
| deepseek-r1:14b | 中档 | 12 - 16 GB 的 VRAM | 单 CPU (i7/i9) 或双 CPU (Xeon Silver 4114 x2) | 16-32 GB | 9.0 GB |
| deepseek-r1:32b | 中档 | 24 GB 的 VRAM | 双 CPU (Xeon Silver 4114 x2) | 32 - 64 GB | 20 GB |
对于 671b 模型,大约需要 480 GB 的 VRAM。必须使用多 GPU 设置,例如:
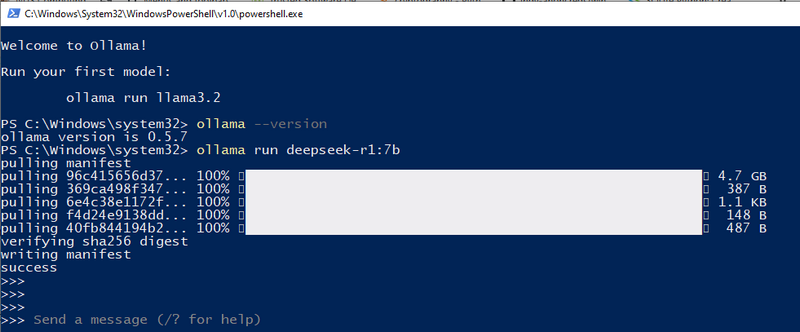
参考: 1.3 下载并运行 DeepSeek-R1 对于我的本地配置,我使用 3060GPU(12GB),所以我可以尝试 7b。我们可以使用 ollama run deepseek-r1:7b
现在,DeepSeek-R1 已成功部署在您的本地机器上,您可以开始直接从终端提问 AI 问题。 步骤 2:安装 nomic-embed-text为了构建 RAG(检索增强生成)知识库,我们需要 nomic-embed-text,它可以将数据(例如 PDF 文件或文本字符串)转换为向量表示。这些向量嵌入使 AI 模型能够理解不同文本片段之间的语义关系,从而提高搜索和检索的准确性。 2.1 下载 nomic-embed-text 访问官方页面:https://ollama.com/library/nomic-embed-text 并下载最新版本,如下所示:
您还可以直接使用 Ollama pull 命令安装 nomic-embed-text: ollama pull nomic-embed-text
步骤 3:安装 AnythingLLM 并部署 RAG为了设置 RAG(检索增强生成)系统,我们将使用 AnythingLLM,这是一个开源 AI 聊天机器人,可以与文档进行无缝交互。 3.1 下载并安装 AnythingLLM 访问官方 AnythingLLM 下载页面:https://anythingllm.com/desktop 并下载适合您操作系统的安装程序。
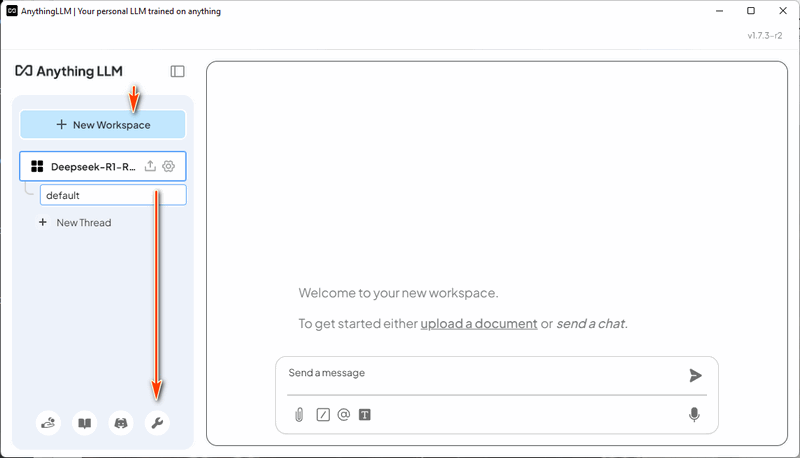
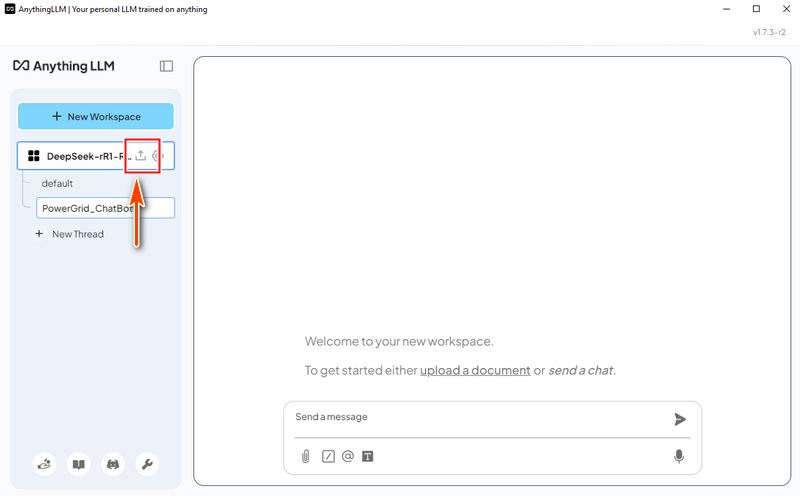
3.2 创建工作区 安装并运行 AnythingLLM 后,创建一个名为 "DeepSeek-R1-RAG" 的新工作区。然后,单击工作区的 "打开设置" 图标,如下所示:
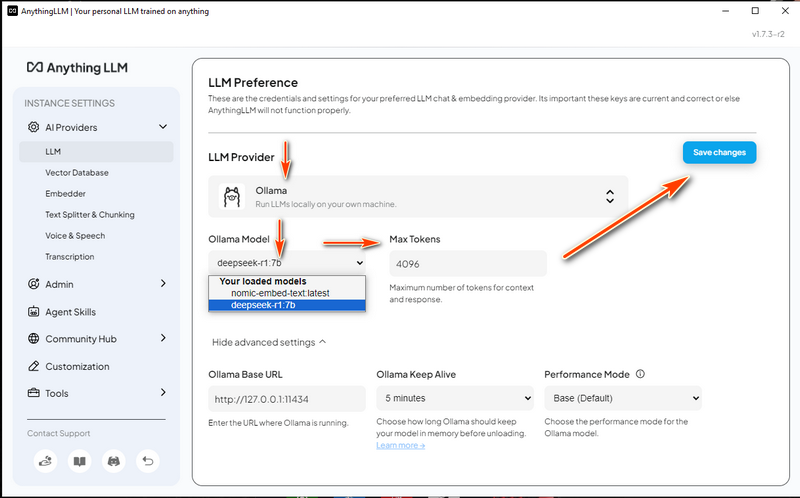
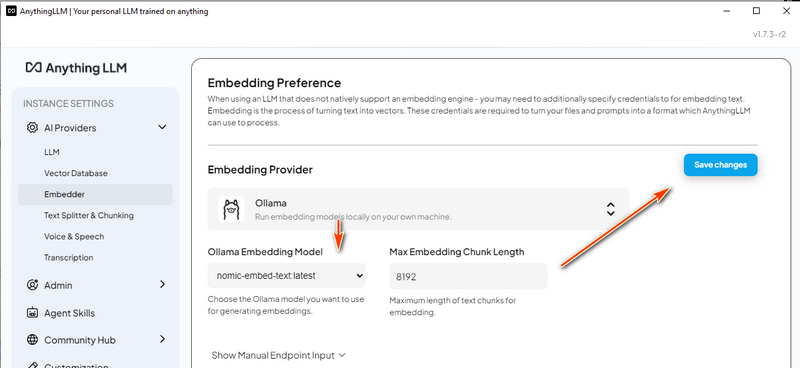
3.3 配置 LLM 设置
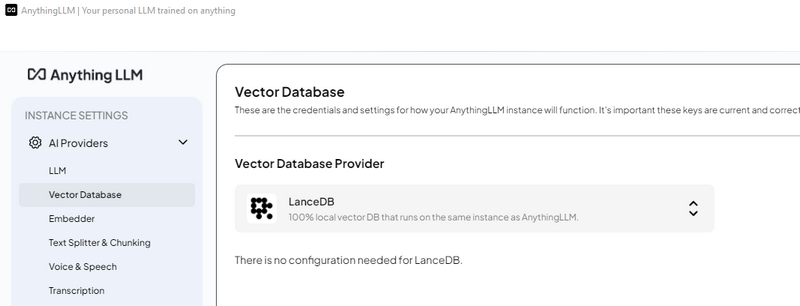
3.4 配置向量数据库
3.5 配置嵌入模型
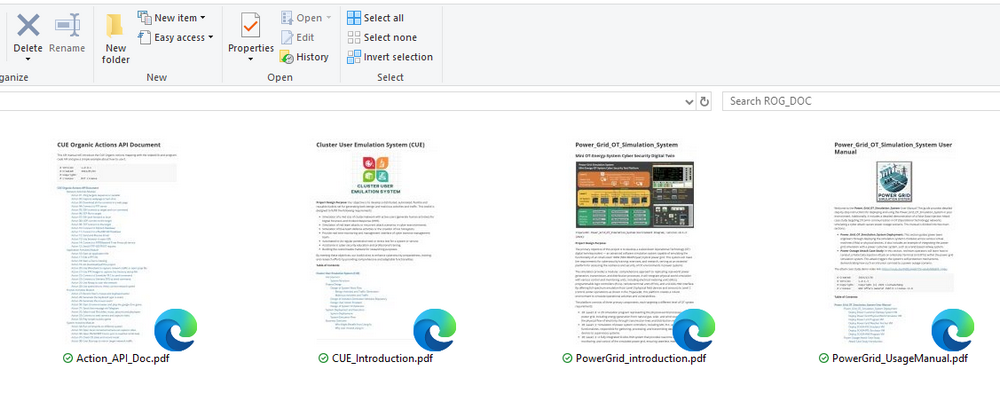
步骤 4:加载 RAG 数据并开始测试现在我们已经完成了设置,我们可以将文档加载到 RAG 系统中并测试 DeepSeek-R1 聊天机器人。 4.1 准备知识库 我们将使用四个PDF 文档来构建 AI 的知识库:
电力网格仿真系统文档
集群用户动作仿真 (CUE) 系统文档
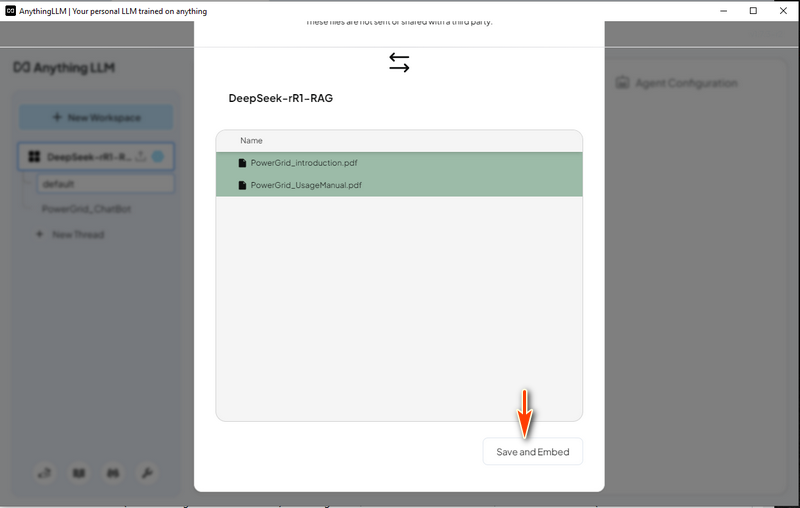
4.2 加载电力网格系统数据 在 AnythingLLM 中,创建一个“Power Grid Chat Bot”线程并单击上传图标:
然后选择“Save and Embed”,如下所示,在进度完成后,带有 RAG 的 LLM 即可使用。
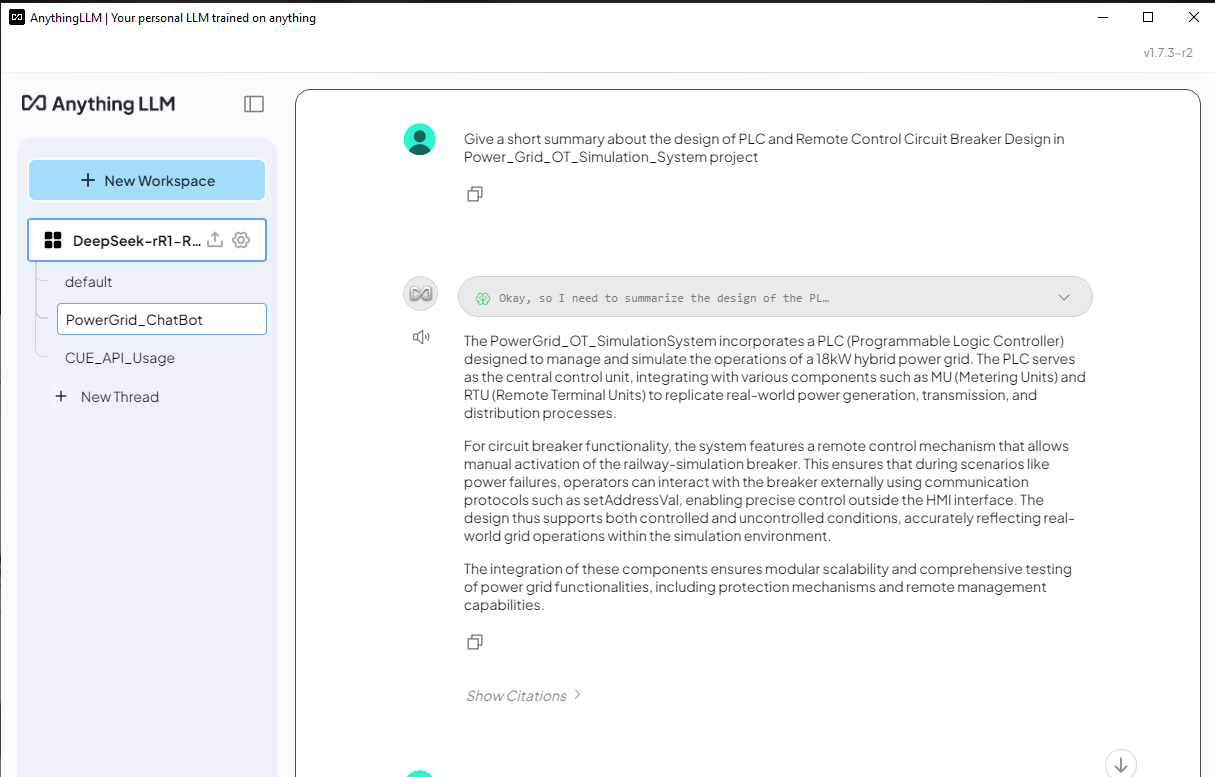
4.3 使用电力网格数据 RAG 测试 DeepSeek-R1 聊天机器人 现在我们可以尝试向 DeepSeek-R1 提出一个与电力网格仿真系统相关的问题,并比较有 RAG 和没有 RAG 的答案之间的结果。 问题: 简要概述 Power_Grid_OT_Simulation_System 项目中 PLC 和远程控制断路器的设计。
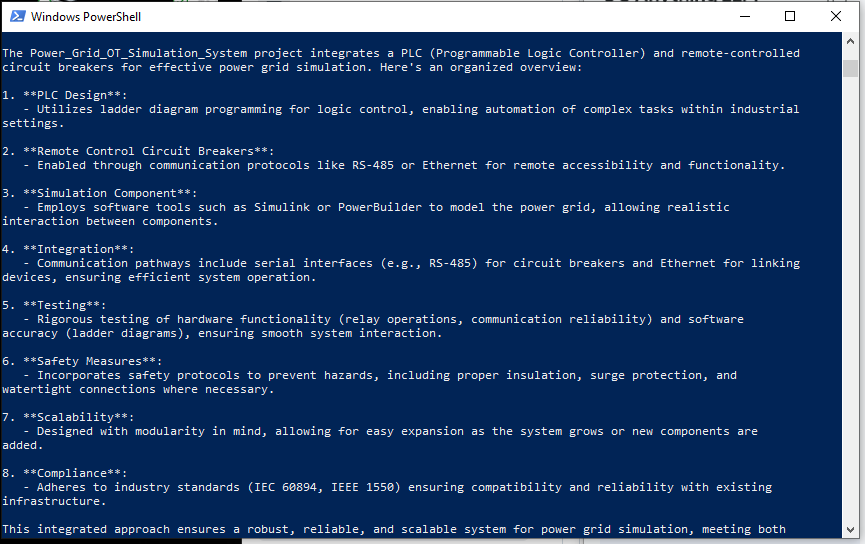
DeepSeek-R1(没有 RAG)的答案- 对于没有 RAG 的 DeepSeek-R1,它列出了一个非常笼统的答案,如下所示,并且该响应与 Power_Grid_OT_Simulation_System 项目无关:
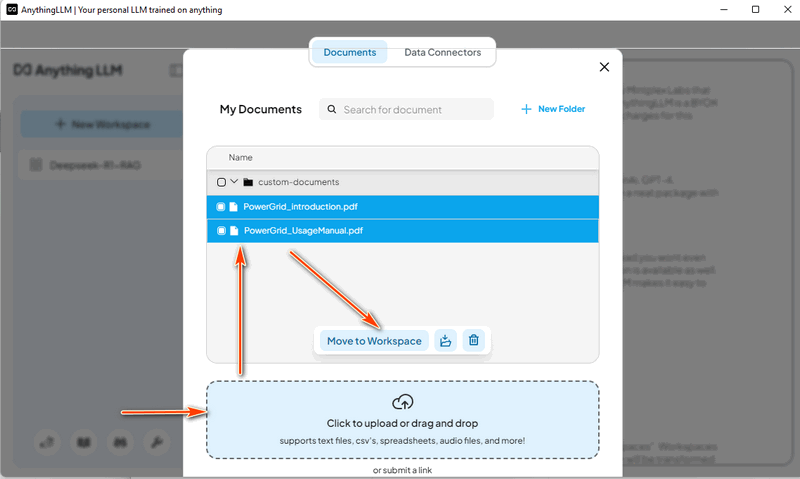
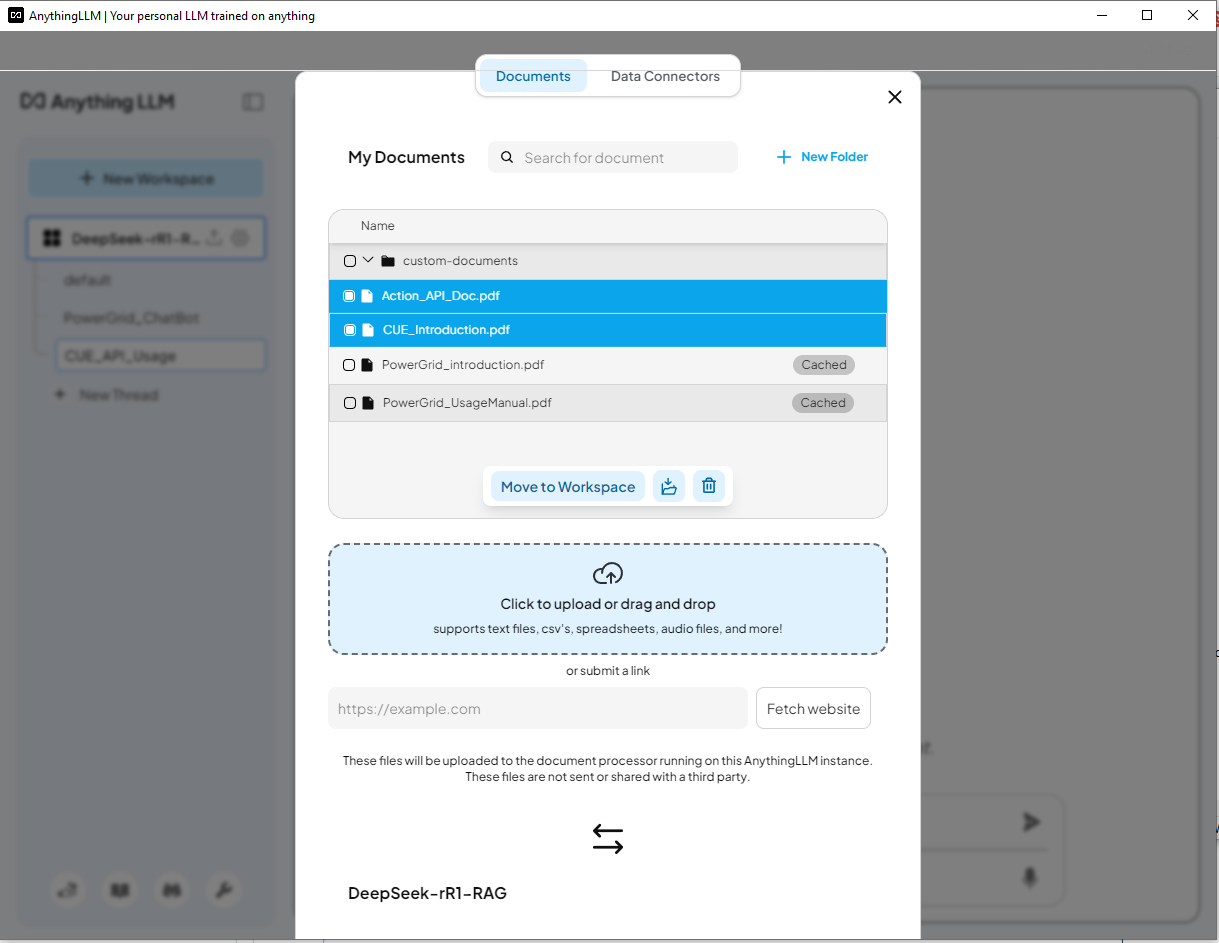
4.4 加载 Cluster User Action Emulator Project 数据 这次我们移除 power grid doc,并加载 Cluster User Action Emulator Project 的介绍文档
4.5 使用 CUE 数据测试 DeepSeek-R1 ChatBot 现在我们可以尝试向 DeepSeek-R1 提问一个关于使用集群用户行为模拟系统中的 lib 函数创建 python 脚本的问题。 问题: Help create a python script/function uses the cluster user emulator(CUE) function API to ping an IP 192.168.10.100 and ssh login to the server with (username: admin, password: P@ssword) to run a command "ifconfig"
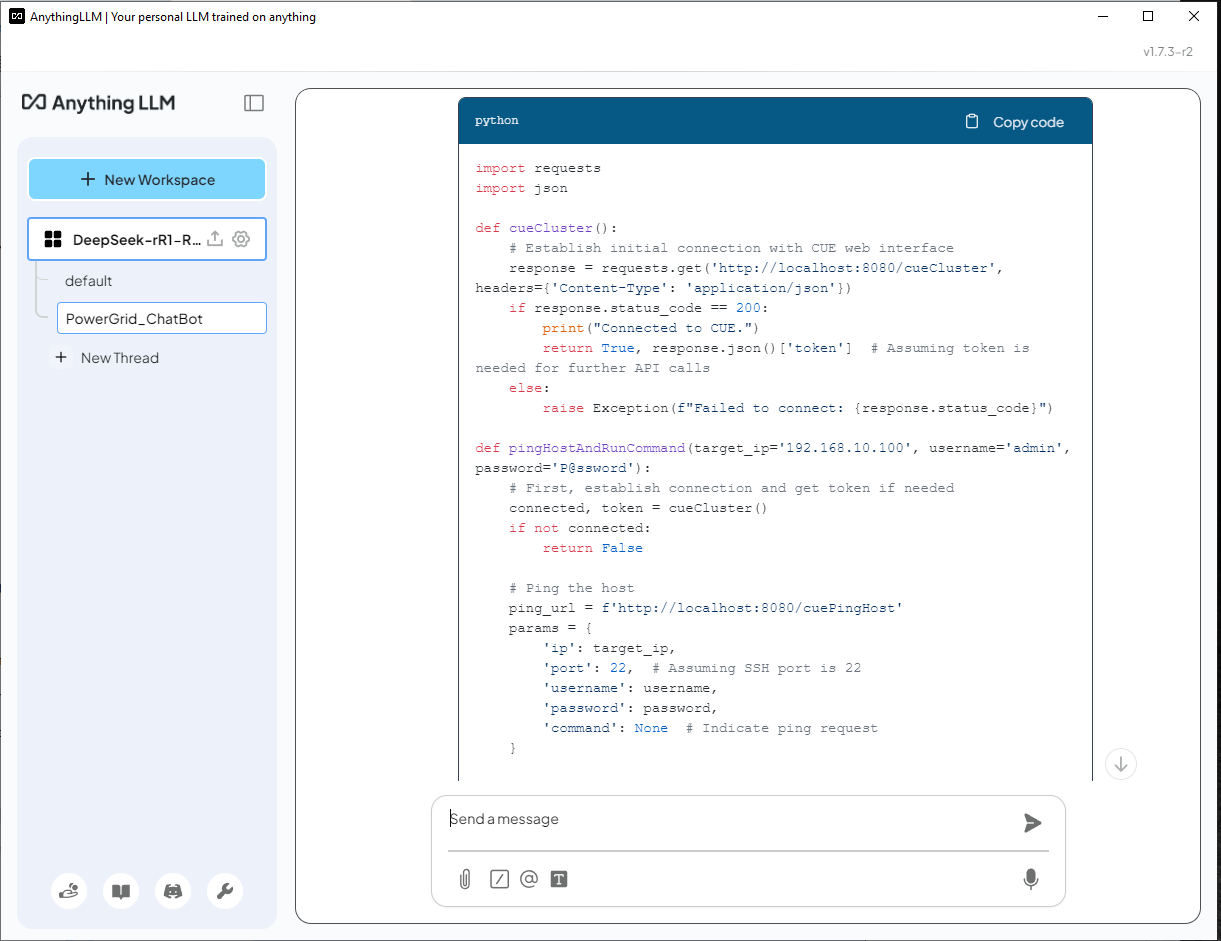
DeepSeek-R1 (不使用 RAG) 的回答 - AI 无法识别 CUE,并错误地使用
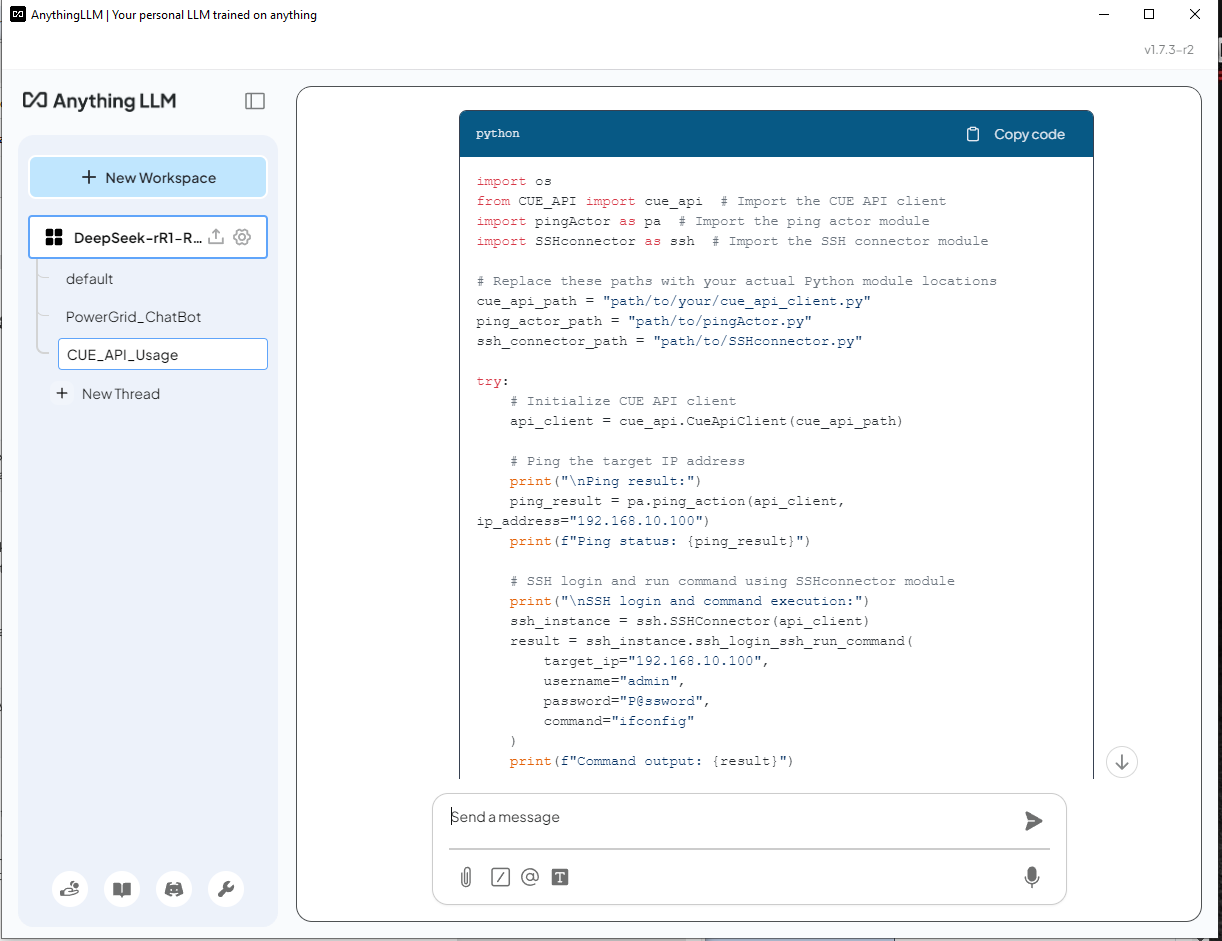
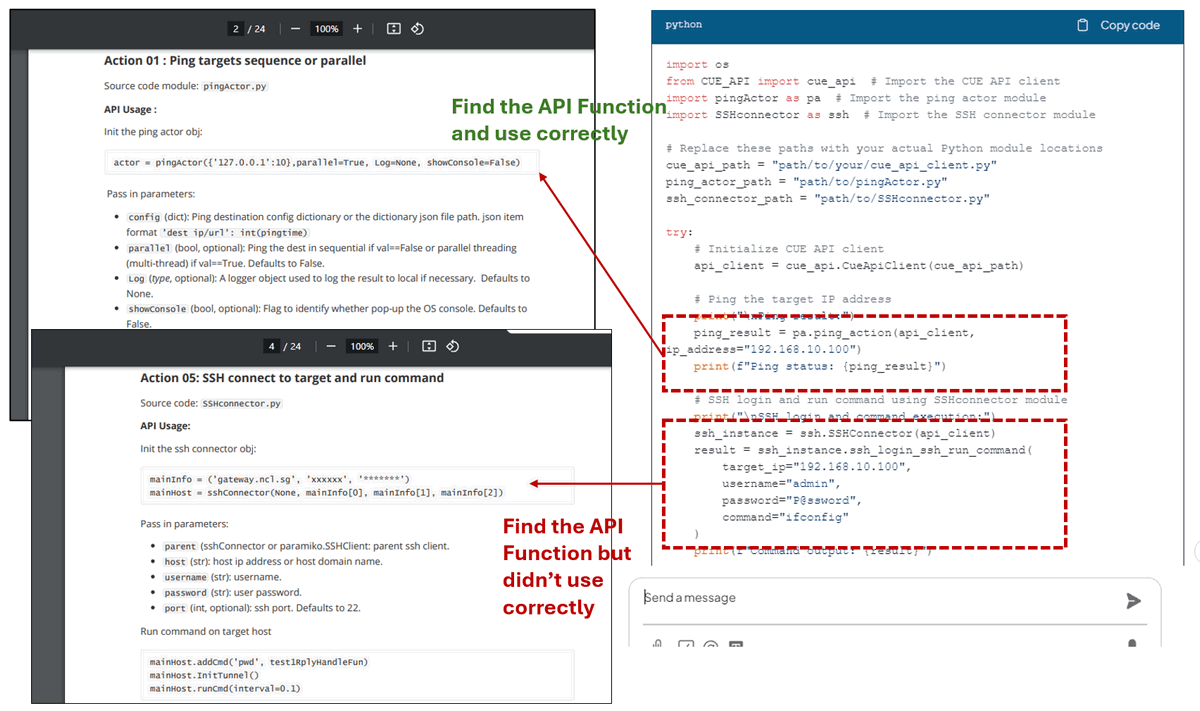
正如我们所见,DeepSeek-R1 使用了 API 文档中提供的正确的 lib 模块来构建脚本。对于 ping 操作代码,它从第 2 页的 API_document 中找到了正确的 API 函数并正确使用。对于 SSH 操作,它从第 4 页的 API_document 中找到了正确的 API,但它没有正确初始化连接器对象:
启用 RAG 后,DeepSeek-R1 可以根据特定领域的文档生成响应,使其比标准模型更准确和有用。但是,仍然需要审查 AI 生成的代码以确保正确性。 结论通过使用自定义检索增强生成 (RAG) 知识库在本地部署 DeepSeek-R1,可以实现具有增强的特定领域专业知识并同时保持数据隐私的 AI 驱动的应用程序。通过利用诸如 Ollama、nomic-embed-text 和 AnythingLLM 之类的工具,用户可以构建智能聊天机器人、代码生成器和针对其独特需求量身定制的 AI 辅助决策系统。标准 LLM 响应与 RAG 增强的答案之间的比较突出了集成外部知识源时在准确性和相关性方面的显着改进。这种设置不仅提高了 AI 的可靠性,而且确保了专有数据的安全,使其成为寻求本地化 AI 驱动的洞察力的企业、研究人员和开发人员的强大解决方案。
RELATED1 COMMENTPROGRAMMER HUMOR
SUPPORT USIf you find this article helpful, please consider supporting our work. DONATEABOUTHOW IT WORKSFOLLOW USFEEDBACK |

Great Introduction! Thank you!