Background
In distributed systems, there is one effect where the unavailability of one service or some services will lead to the service unavailability of the whole system, this is called service avalanche effect. A common way to prevent service avalanche is do manual service fallback, in fact Hystrix also provides another option beside this.
Definition of Service Avalanche Effect
Service avalanche effect is a kind of effect where the service provider fails to provide service which causes the service caller also fail to work. And this kind of service unavailability will propagate to the whole system gradually and in turn the system down.
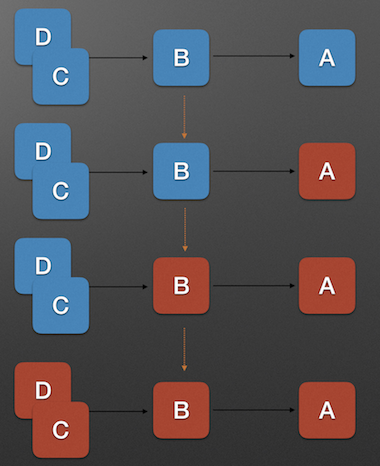
In above diagram, A is the service provider while B is the service caller, C and D are service caller of B accordingly. When service A is unavailable, it leads to the service unavailable of B and in turn service unavailability of C and D. This is a service avalanche effect.
The Causes for Service Avalanche Effect
There are two participants in the service avalanche effect: service provider and service caller. And there are three phases for the whole process of service avalanche effect.
- Unavailability of service provider
- Requests increase due to retry
- Unavailability of service caller
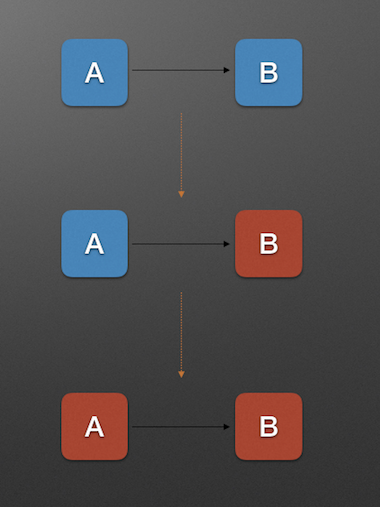
There are different causes for service unavailability in different phases. For example, below are some of the causes for why service provider is unavailable.
- Hardware fault -- Hardware damage may cause the server down. Or network device damage would cause the network not able to access
- Software bug
- Cache breakdown -- This happens when cache service is restarted and all the cached data are gone or lots of cached data expire. This will cause the request to directly hitting database which increases the load for the database.
- Mass requests -- When some promotional event is launched, lots of requests from users
And the causes for the request retry are:
- User retry -- When service is unavailable, user would keep refreshing the page continuously because they don't want to wait for the loading
- Code logic retry -- There would be lots of retries in code logic when service is unavailable
And the causes for why service caller is unavailable are:
- Synchronization causes resource unavailability -- When service caller has lots of synchronous calls, there will be lots of waiting threads which would consume system resource. When the system resource is exhausted, the service would be unavailable.
Resolutions for Service Avalanche Effect
There will be different resolutions for different causes of the avalanche effect.
- Traffic control
- Improve cache model
- Service auto-scale
- Service caller fallback
The detailed steps for traffic control include:
- Gateway traffic control
- User interaction control
- Disable retry
Nginx+Lua are used for achieving the gateway level traffic control given that it has very high performance. Hence OpenResty is becoming more and more popular.
There are normally two ways to control user interaction
- Using loading animation so that users can tolerate longer waiting time
- Submit button adds force waiting time
The ways for improving cache model are
- Cache pre-loading
- Sync to Async of cache update
Service auto-scaling includes:
- AWS auto scaling
Service caller fallback includes:
- Resource isolation
- Categorize dependant service
- Fast responding for unavailable service
Use Hystrix to Prevent Service Avalanche Effect
Hystrix is a library developed by Netflix to provide protection to the system when service times out or other service issues.
The design principles of Hystrix are:
- Resource isolation
- Circuit breaker
- Command pattern
Resource isolation
Normally a container ship will have many different isolated spaces to prevent the sink of the ship in case of water leak or fire.
This kind of method is also called Bulkheads,. Hystrix adopts the same mechanism on service caller. Let's take a product display system as example.
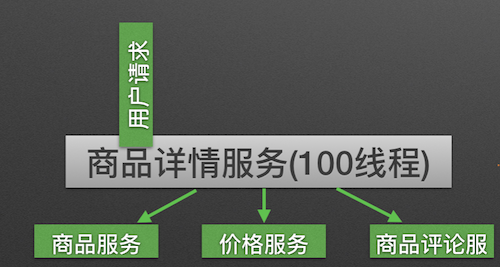
A product detail service will depend on product service, price service and product comment service. When calling the three services, all of them will share the same thread pool of product detail service. If the product comment service is not available, then all threads would be blocked because they need to wait for the product comment service. This would finally cause the service avalanche effect.
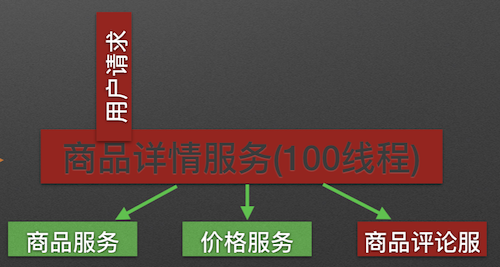
Hystrix will prevent service avalanche effect by allocating independent thread pool for the dependent product detail service.

Circuit breaker
Circuit break defines the logic of toggling the switch to on and off. The health of a service is defined by the failed requests/total requests.
The state change of the circuit break is determined by service health condition and a threshold.
- When circuit breaker switch is off, requests are allowed to go through the circuit breaker. If the current health condition is larger than the threshold, the switch will remain off. If the health condition is smaller than the threshold, the switch will be on
- If the switch is on, no request will be allowed
- When the switch is on, after a while, the circuit breaker switch will be half on. Now in this case, only one request will be allowed to test the health condition. When the request is successful, the switch will be turned off, otherwise it will still remain as on.
This mechanism will ensure that the service caller will quickly get response when the service provider is in an unhealthy condition.
Command pattern
The Hystrix command pattern will encapsulate the command run logic(run) and the logic for fallback(getFallback) when the service call fails.
The details fo this pattern are:
-
Construct the Hystrix command object, and call the run method
- Hystrix will check whether the circuit breaker switch is on, if it's on, then call the fallback method
- If the circuit breaker switch is off, then Hystrix will check the thread pool of current service to see whether it can accept new request. If thread pool is full, then call fallback method
- If the thread pool can accept new request, then Hystrix can call the run method to execute the run logic
- If run executes fails, then call fallback method and return the health condition to Hystrix Metrics
- If run executes timed out, then call fallback method and return the health condition to Hystrix Metrics
- If run executes successfully, then return normal result
- If fallback method executes successfully, it will return the fallback execution result
- If fallback method executes failed, throw exception
Conclusion
Hystrix can greatly help prevent service avalanche effect by auto fallback and auto recover when service is in unhealthy state. It is now being used in lots of distributed systems to ensure teh availability of services.
