In some cases, one would want to convert a HTML string to the DOM elements so that JavaScript can handle them easily. This is frequently used when one get some data from third party APIs where the data is in HTML format.
In JavaScript, there are a couple of ways one can use to convert HTML to DOM elements.
- DOMParser
- document.createElement
DOMParser
DOMParser can parse XML or HTML source stored in a string into a DOM Document. After the conversion, the normal JavaScript call of handling DOM elements can be used, like getting element by id or using selectors.
For example, assuming there is a HTML string
<div id="test_div"> <ul> <li>Item 1</li> <li>Item 2</li> <li>Item 3</li> </ul> </div>
Now it can be parsed using below code.
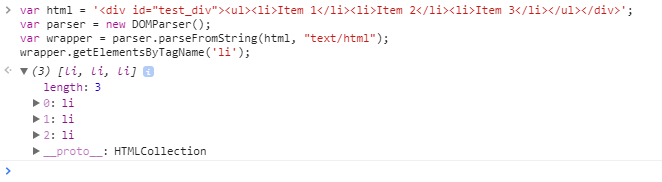
var html = '<div id="test_div"><ul><li>Item 1</li><li>Item 2</li><li>Item 3</li></ul></div>';
var parser = new DOMParser();
var wrapper = parser.parseFromString(html, "text/html");
wrapper.getElementsByTagName('li');
The output looks as expected, there are three objects returned.
One thing to keep in mind is that the DOMParser is still an experimental feature and is not standardized yet though many main stream browsers have supported it. And this feature is not supported in old browsers.
document.createElement
Another way of converting HTML to DOM is to use the traditional document.createElement method. After creating the element, the HTML string can be assigned to the innerHTML attribute of the element and the JS engine would parse it to the child elements of the created element.
For the same HTML string above, the code using document.createElement would be
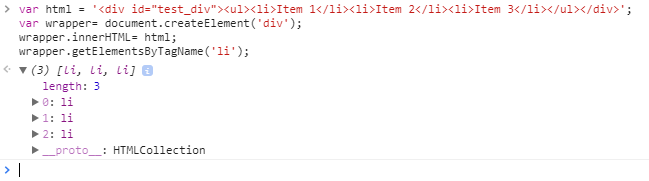
var html = '<div id="test_div"><ul><li>Item 1</li><li>Item 2</li><li>Item 3</li></ul></div>';
var wrapper= document.createElement('div');
wrapper.innerHTML= html;
wrapper.getElementsByTagName('li');
The output would also be expected.
Note when setting the innerHTML, if the string contains elements like images which require loading, they will be loaded at parse time. This would sometimes not be expected since they may trigger unnecessary network connections. Or it would impose potential security risk where malicious JavaScript code would be loaded.
Normally one should use DOMParser if he can but if the application needs to support old version of browsers, these two methods should be combined and a wrapper method should be created on top of them.

Poop